Remove SQL Alchemy – Performance edition¶
Status: Draft Review status: Draft Theme: DX, Performance, Pre-existing PG
Team¶
Project owner: Brent
| Role | Assignee | Reviewer | Notes |
|---|---|---|---|
| Requirements | Brent | Dom, Pavish, Kriti | Product spec, requirements, GitHub issues |
| Backend work | Brent, Anish | Anish, Brent | Backend specs and code |
Problem¶
- Mathesar’s performance is bad when there are a large number of database objects, under any conditions.
- Mathesar’s performance is bad to the point of unusability when there’s any network latency between the web service and the user’s database(s).
Example¶
To exemplify the performance problem, I set up a test DB with:
- an empty
publicSchema, - 3 schemata,
- 5 tables per schema,
- 8 columns per table, and
- 10 rows per table.
I added 50ms of latency to calls between the web service and the DB, in order to simulate a non-colocated setup (50ms is pretty quick, actually; From me to our internal.mathesar.org DB is more like 200ms). I then performed the following user flow:
- Login
- Click a random schema.
- Click a random table in that schema.
- Add a
TEXTcolumn to that table. - Navigate back to the schema page (i.e., where the tables are listed)
- Add a table from import (patrons_sim.csv, no type inference).
Below is a screenshot showing the recorded times for all requests to http://localhost:8000.
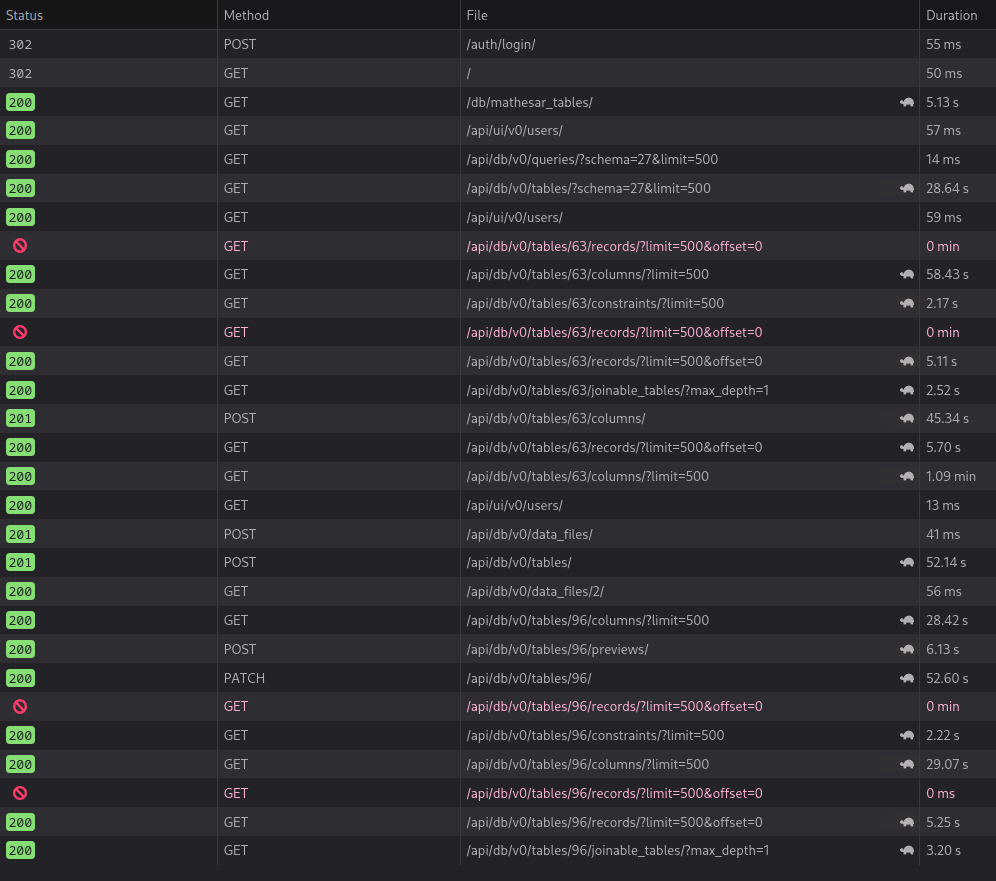
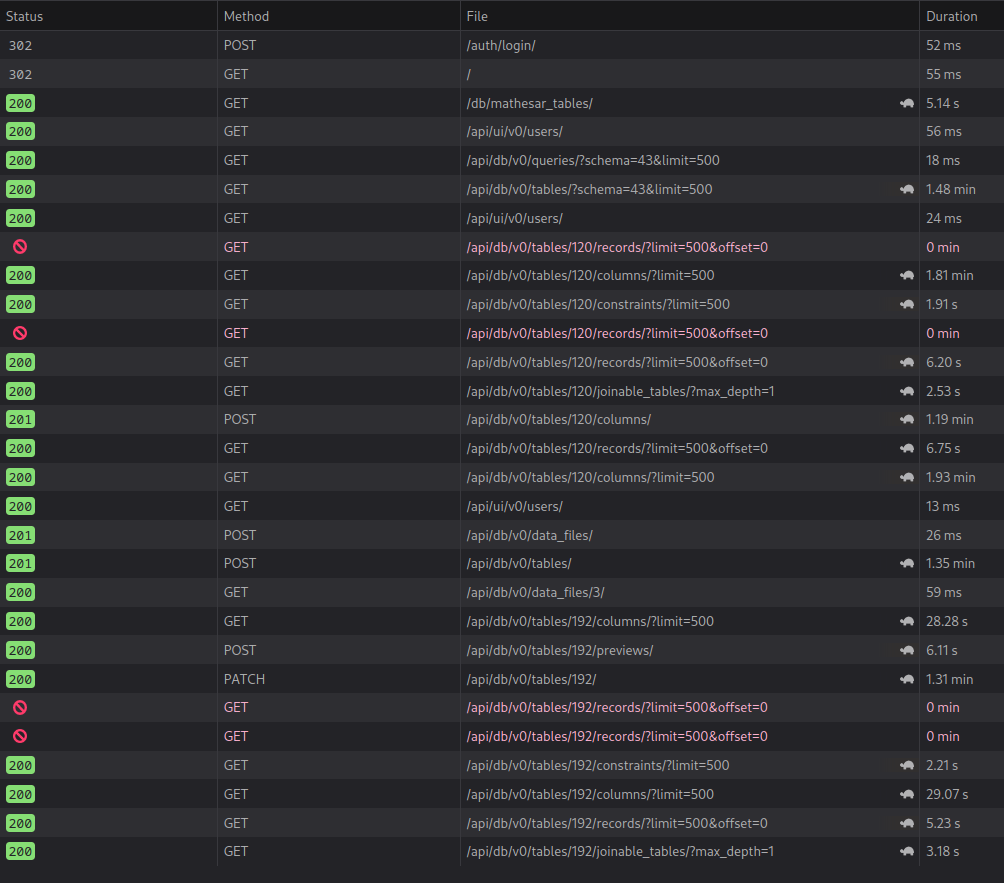
More tables, or columns per table makes the situation worse. Here’s the same experiment, with the single change of having 10 tables per schema, with 15 columns per table:
Solution¶
We should tackle the slowest endpoints above (and maybe the column inference endpoint), removing all SQLAlchemy reflection calls from the code paths.
Outcome¶
The endpoints we fix should run noticeably faster (I expect by a factor of 100x)
Risks¶
We need to rearchitect how these calls work for this to be feasible.
Links¶
TODO
- Issues: GitHub meta issue
- Wiki pages:
- Product spec
- Backend spec
- Frontend spec
- Email discussions:
- Weekly updates
Timeline¶
This project should fit into the 2023-01-01 cycle.
Information
Please adjust as needed depending on the steps for the project.