List data type report - 2023 internship¶
In this report we will talk about the scope and goals of the project: List data type. Considerations and difficulties are also discussed, as well as the project’s current state. Finally, a future work line is given.
Introduction¶
The List data type project is about adding support to the Array Postgres type in Mathesar. One important detail to highlight is that we were only going to consider the 1-dimensional case of arrays, as this is the most common use case (and it was also going to save us dealing with some complexities that we’re going to review below). The features originally proposed to be implemented are detailed in the [project’s page]/archive/product/projects/2023/07/list-datatype).
Preliminaries¶
An Array is not a data type per se, but a data structure that holds values of a certain data type. It is not supported by all the SQL databases, but Postgres does. A common array is a structure characterized by having a length and dimension. E.g.
a = [1, 1, 3] # a has length=3 and dimensions=1
b = [[1, 1], [2, 3]] # b has dimensions=2
c = [[[1, 1, 1]]] # c has dimensions=3
array_length function, which needs to be passed the dimension as an argument, so it returns the number of items at that dimension.
SQL Alchemy (SA) support¶
This library supports the handling of arrays, and it implements it as a data type class with an item_type attribute that specifies the true data type in the DB.
The Array class also uses an optional dimensions argument, with a default value of 1. This does not actually reflects into an ARRAY column enforced to be 1-dimensional in the DB; it’s just a hack of the library to traverse the arrays more efficiently when converting them to Python’s lists.
Warning
Attention, SQL Alchemy needs to work with the psycopg2 DB API to manipulate arrays.
Methodology¶
Restricting the dimensions to one¶
Our initial goal was to support 1-D arrays. For this, we assumed the following:
- Having access to a length and dimensions properties
- An ARRAY[…] column contains records with a maximum number of dimensions and length
However, this was not true.
Arrays in PostgreSQL The implementation of Arrays in PostgreSQL is tricky, and for our project, it brought a big overhead. From [1]: ”… the current implementation ignores any supplied array size limits, i.e., the behavior is the same as for arrays of unspecified length. The current implementation does not enforce the declared number of dimensions either. “
Problems:
1. We cannot be sure now that all the values in an ARRAY column will have the same dimensions and length.
2. Users can create ARRAY columns with N-dimensions back with Postgres, and Mathesar would have to figure out how to render them.
3. Any display option that the Frontend usually handles per column would now need to be processed per cell.
4. We cannot give users the chance to create a List column with a fixed number of dimensions, and assure them that all the records will comply with that number of dimensions.
In summary, we don’t have control over any dimensions nor length properties, because they are not even considered in the Postgres implementation. Some ideas on how to implement the Array type are going to be discussed now.
Custom Mathesar Type¶
Similar data types like JSON and JSON Arrays have been implemented as custom data type classes in Mathesar. As such, they are reflected as Domains on the DB. Implementing Arrays in this way has some issues:
- As any data type can have its Array version, this implies that Mathesar will have to create a Domain for every possible scalar type.
- We would not have an Array type for any other scalar type installed on a user’s DB (any custom type that Mathesar is not aware of).
- Other aspects tied to a data type, such as cast functions, will also be multiplied by this factor.
- This can be dangerous for backwards-compatibility in the future; we would have to support both a constrained array version and an unconstrained one (for when Mathesar does give full support to n-dimensional arrays).
Type decorator in SA¶
Another option was to implement the Array as a class that inherits from SA’s TypeDecorator [2]. The catch here is to access to the dimension’s argument handled by SA, and in compiling time, making sure that we pass a value of 1. Again, this workaround also has some disadvantages:
- Mathesar is currently trying to reduce its dependence on SQLAlchemy.
- We need to support columns being written to in the database via other clients (i.e., where the enforcement won’t happen). That dimension can’t be reflected from the database.
Also while trying to integrate this class to the project, I faced difficulties such as:
- Mapping between this and the results of Array aggregation operations. I managed to solve it by using the kwarg
_default_array_typeof thearr_agg()method of SA, and set as its value my TypeDecorator class. - Issues with casting that affected other functions, like
get_constraint_record_from_oid(). This function is used to retrieve attnums of columns that have constraints, and outputs a list. After installing the new decorator, this function casted the array to text, breaking tests like the ones intest_constraint_api.py.
The difficulty of introducing this decorator in the codebase and the type of changes required are indicative of the type of problems that could be found porting other pseudo data types.
Custom adapter¶
It would give us more control if we develop a module that works directly with psycopg2, where we could fully handle the postgres-python (and vice-versa) mapping of arrays. This module will also (probably) help us fix format issues when aggregating records of date like data types. See issues #2962, #2966. Custom adapters for date-related data types are discussed in the psycopg2 documentation, as some exact mappings are not possible [3].
This option will however, require more time both for planning and implementation, as this would be a new way of implementing a data type in Mathesar, possibly requiring modifications in several parts of the backend code; e.g. integration in the codebase will be more complex. Moreover, it works mostly on Python’s side, meaning we are not enforcing anything on the DB side.
Supporting n-dimensional arrays¶
Given that none of the ideas we had to attempt restricting arrays to 1 dimension were successful, we now move to consider supporting multidimensional ones.
Filters As reviewed earlier, operations over n-dimensional arrays become confusing.
-
Length: it needs to know over what dimension to count.
-
Contains: Postgres will internally store an array as a 1-dimensional one [5], so when comparing if a multidimensional array is contained in another one, it can behave weird.
So, it’s like, before comparing, Postgres engine unnests the arrays involved in the comparison, and it will check if each value on the right-hand side array is present in the array to the left. -
Sort: there can be different criteria for sorting records of an Array column, and it becomes less intuitive/clear to compare and sort n-dimensional arrays. In addition, each possible scalar type has its own criteria for sorting.
Summarization Grouping records of a given column is currently supported. In the backend, the SA function array_agg() is used for this purpose, and it returns an object of SA’s Array [6] type. However, if we now deal with arrays as records, grouping them can lead to inconsistencies in the inner dimensions of the Array. For example:
| name | emails |
|-------|--------------------------------------------|
| alice | '{"alix@gmail.com"}' |
| alice | '{"alice@hotmail.com', "bbb@outlook.com"}' |
# grouping by name here will have to aggregate as:
'{{"alix@gmail.com"}, {"alice@hotmail.com', "bbb@outlook.com"}}'
# but this is not possible in Postgres
Rendering format Currently, each data type in Mathesar has its own UI component. A list also has its own styling, which is currently rendering pills in the data explorer. What should we display then, for a list of dates? Including a date picker inside a pill does not sound user-friendly. Now, consider a multidimensional array of dates. What’s the best way of rendering it? Without overloading the frontend and overwhelming the user who wants to edit one item/element.
Current state and considerations¶
Backend¶
There is no new data type for arrays; the SA’s Array [6] type, which was already supported for aggregation transformations, is the one we’re going to keep working with.
CRUD operations¶
Sending a patch request (update) to an array column correctly updates the records in a table. A request looks like this:
where 125 is the id of the column to be updated, and the value is an array. Reading is also working well for 1-D arrays.
Next steps:
- Test through API client: create and delete column.
- Tests for n-d case, in particular, when reading the data, how does the mapping of SA work (i.e how the formed array look like)?
- Type options dict properties: length and dimensions, should be discarded.
Filters¶
These filters are supported:
- ArrayLengthEquals
- ArrayLengthGreaterThan
- ArrayLengthGreaterOrEqual
- ArrayLengthLessThan
- ArrayLengthLessOrEqual
- ArrayNotEmpty
- ArrayContains
The filters are implemented with sql functions, which need to be passed a dimension value.
In the case of ArrayContains, we have to make sure it uses the correct operator, e.g. the proper SA comparator class.
Next steps:
- Fix dimension value to 1 for all the filtering operations.
- Test output for n-d cases.
- Test for other scalar types.
Summarization¶
Status: currently not supported.
Next steps:
- Disable grouping by an Array column.
- After: develop custom criteria that avoids dimensions mismatch, for example, a criteria that first computes a single value per row in an Array column. Reducing each record of an Array column to a single value will result in, when grouping, a 1-D array.
Other operations¶
Not supported:
- Distinct
- Sort by
Next steps:
- Disable them for Array columns.
- After: use a criteria that reduces an array to a single value, and then sort.
Frontend¶
Here is where most new things to be implemented take place.
Creating an Array column¶
Status: currently not supported.
Any data type can have its “array version” . Therefore, it doesn’t seem a good idea to list each possible Array type in the data types dropdown list:
- There will be a lot of options listed.
- The user can easily misread one list type and select a wrong one, for example, choosing List of Money instead of List of Email (both begin with ‘List of …’).
A cleaner approach suggested by Ghislaine [4] is to have a separate menu for the Array or List type.
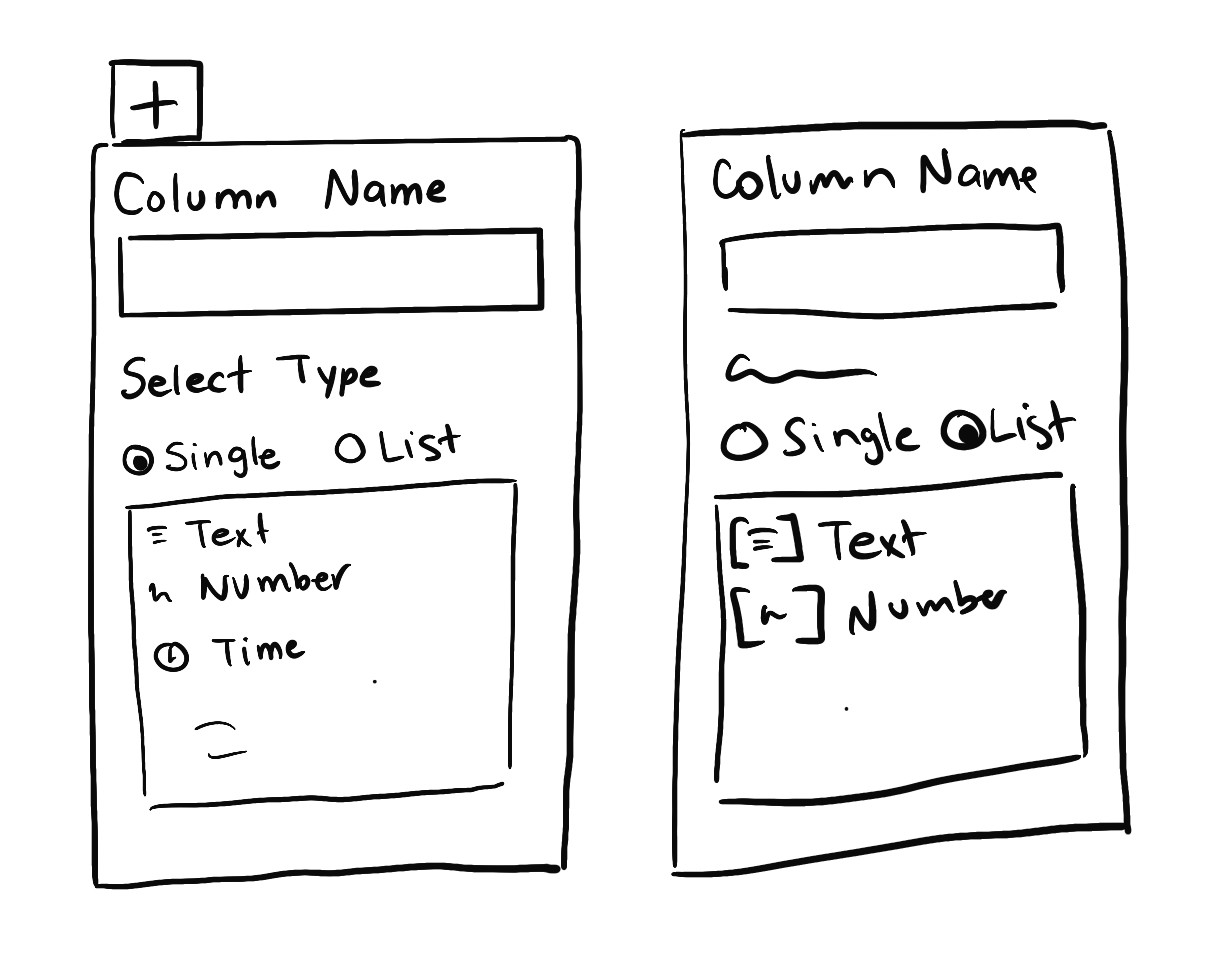
Also, consider using the term “Array” instead of “list”, as the first one encloses n-dimensional arrays too (which will be supported in the future) and operations that work with them.
Rendering an array¶
For 1-D arrays, items are displayed inside a pill, which corresponds to the Chip component in the frontend. The pills are not modifiable.
The ArrayCell component receives a list object and renders a pill per each value. Currently, it is not handling any length or dimensions property. This is convenient as, for an Array column, we can have any number of elements and dimensions per record.
Also, this approach is not considering the case of N-D arrays. Here, it would be better to render them as plain text. N-D arrays are not used as much as 1-D arrays (people would prefer to go for a vector type instead), so their use cases will be, hopefully, rare. For a first version, it’s not worth to delay supporting it until figuring out how to design a proper UI for this multidimensional structure.
Next steps:
- Keep disabled the edition of pills.
- Detect and display n-dimensional arrays as plain text.
Editing arrays in cells¶
Array columns are read-only, and 1-D arrays are rendered with pills (one item in one pill).
Idea: When editing a cell, a first and basic approach would be to let the user type in the array in the correct format (e.g with brackets, elements separated by commas). Then, as it happens for the other data types, when the user leaves a cell, a call is made to the API to update a particular record.
Work regarding this approach can be found in this branch. Here, cells of an Array column can be edited. Two types of components are handled: TextInput for when editMode=True, and ArrayCell otherwise. There are some issues:
When entering a new value, the Frontend sends to the backend a malformed array, for example:
This is because making both components work in sync is complex. There is probably a mishandling of the TextInput value, and so the Array factory ends up with a string instead of an Array object. More debugging is needed here.
Next steps:
- Enable edition from the record view. The user will have to type the array in the correct format.
- Same for the table view, the user can click over a cell and edit the array as plain text.
Deleting items¶
It is currently not possible to delete elements from an array. Also, the UI/UX has to be sorted out for this functionality.
- Will users be able to delete individual items? Consider the added complexity to this task if the array is large; it’s very easy for the user to loose sight of the element they want to eliminate.
- An easier and reasonable first approach is to let the user handle this through plain text edition. Also, we should think about the persona of the target users. It’s more natural for a DB maintainer to just edit records through a form, using plain text.
Moving elements¶
A drag-and-drop feature does not seem to be very useful to offer.
- Again, we should consider the complexity of this task for large lists.
- For sorting, for end users used to calc documents, making use of a formula to achieve this is more intuitive and comfortable.
- I suggest to test the demand of this feature first before thinking on implementing it. One idea is through a poll.
Documentation¶
User documentation Currently, there is no documentation for the List data type. It would be nice to have a page that explains:
- How to create an Array or List column
- How to edit it
- How transformations and summarization work
- What is currently supported and what’s not
- etc.
In particular, as it was previously discussed, operations for n-dimensional arrays can become confusing, so it would be good to have a section that explains how they work.
Developer documentation When supporting this data type, it would be good to have documentation about the same aspects mentioned before, but for developers, e.g. at a more technical level. It should be included:
- Transformations: what operators are used, sql functions and their arguments.
- Basics of the Array type: how it is implemented (in Mathesar and Postgres), its string form, notions of dimensions and length.
- API: what is sent and what is received.
- What is currently supported and what’s not, for 1-D or N-D arrays.
Conclusions¶
- Major time-consuming task was to figure out how to restrict dimensionality.
- Next step is to make what we have work for the default Postgres’ ARRAY
- Test 1-D case first
- N-D arrays operations can be disabled for the meantime
- New things to be implemented lie mostly in the frontend.
- Documentation is also needed (for both user and developer)
References¶
- Postgres documentation on Arrays
- TypeDecorators
- Custom adapter psycopg2
- Ghislaine feedback on creating a List column
- Contains multidimensional arrays
- SQL Array type in SQLAlchemy
- Slides of project (final presentation): link