Data Management Skills¶
This research project explores the factors that influence the adoption and acquisition of data management skills and how Mathesar can minimize the negative impact of skill gaps in this area.
Data management skills?¶
What are data management skills?¶
Data management skills are learned abilities that allow people to accomplish different goals using data. These skills are applied to various scenarios, such as when working with data as part of a business process or creating data-driven strategies. It’s important to note that data management skills are not necessarily about technology alone. There are also procedural and conceptual aspects that influence proficiency in this area.
Most data management skills fall into the following categories: * Data Assessment * Identify problems with data accuracy, completion, recency * Evaluate coverage and content of a data set * Data Mining * Turn raw data into useful information * Look for patterns in large batches of data * Data Validation * Ensure correct data types are used or entered * Data Analysis * Clean, transform, and model data to discover useful information * Data Storage and Retrieval * Store, manipulate, and retrieve data from a database * Workflow Optimization * Improve the efficiency of workflows that rely on data * Clearly understand a database usage purpose * Produce complete and reliable information of events in a process
Adapting use cases to data management skill levels¶
We rely on use cases to come up with different scenarios and situations where applying Mathesar can solve a user problem. However, if the use case is very complex it can introduce a lot of variables and make it harder to incrementally work on defining and implementing Mathesar’s set of features and functionality.
For example, in the case of tracking health data, as per Kriti’s example:
“Would be great to be able to upload Apple Health exports, Migraine Buddy exports, MyFitnessPal exports, etc. and find patterns in data, correlate different types of data.”
A user looking to accomplish this task will require almost all of the skills listed above, except maybe for SQL and workflow optimization ones. A user will need to obtain the data from different sources, determine the correct data types, combine datasets and identify patterns.
The role of Mathesar in enabling data management skills¶
Mathesar features should aim to alleviate the consequences of data management skill gaps and enable users to accomplish their goals. For example, filtering, sorting, and grouping features can help uncover patterns in large data sets. Providing aggregate metrics such as sums, counts, averages, or others for filtered views could further enhance user’s pattern-finding abilities. We might want to consider these details when thinking about the interface and interaction design aspects for the Mathesar product. However, no product will ever satisfy all user needs, and using Mathesar alone might not work for all user goals. For this reason, Mathesar seeks to simplify integration with other tools and offer extensibility options.
Common Issues¶
Database Design or Breaking Data into Tables¶
Users tend to discover problems related to their initial design too late into the project and have a hard time fixing them without recurring to a lot of manual effort or starting from scratch. If the data is spread over several tables, it can also be much more time consuming to fix data issues. This can happen in cases where they are already using their database to solve an actual problem, making the fix a lot more complicated, for example, collaborators are already entering data. These problems often become visible when the solution needs to scale, such as when adding a new client to a business project. Once the initial solution flaws are uncovered the user is left with few options on how to resolve them. A hypothesis on why this happens is that they aren’t clear on their database’s purpose beyond solving the immediate problem, mainly centered on capturing the data rather than thinking about the entire design. They also lack the appropriate knowledge to diagnose and resolve the issue once they find it, implementing solutions that introduce additional manual work and increases the risk of data inconsistency, duplication, and time waste. Unexpected scenarios can also lead to this in otherwise well-designed databases. For example, the case of a user assuming a one-to-one relationship for a set of entities and then realizing that a one-to-many relationship was possible.
User Quote:
“I worked so hard on creating these tables, and I’d hate to think that I have to completely rebuild the damn things every time I need to use them on a different project.”
“With Airtable, I’ll get good, easy, relationships, with a great UI, but all sorts of garbage in, garbage out (GIGO) problems with the non-relational attribute values.”
Database Relationships or Linked Data¶
Common linked records issues occur when users manually link to other tables or have various linked records across multiple tables. There’s a tendency for users to avoid separating entities into different tables. Some users consider doing this as overkill or see it as a potential factor that will slow them down in the future. They don’t feel capable of keeping track of all tables and fear the complexity resulting from the load. Sometimes users refer to tables as main or child, which might demonstrate an attempt to establish a hierarchy or make the database more manageable. A hypothesis on why this happens could be that users can’t easily plan the relationships between entities or lack the appropriate knowledge to make those decisions, such as knowing the difference between values or entity sets. It could also be that since they lack database querying skills, the idea of too many tables seems unmanageable. Users are reluctant to increase the size of a project if they feel incapable of managing it effectively and might choose sub-optimal ways to structure it.
User Quote:
“Doing changes to the table while having so many fields is difficult because too stuff to plow through in general (e.g. while having many different views with different configuration) and if new fields were added in the table, the fields will need to be moved around in views manually because new fields are added at the end of fields in these various additional views”
“Is there an easy way of knowing if fields in my tables are being used anywhere in the base?”
Roadmap Considerations¶
Based on user research, the ideal roadmap will seek to balance core database management features with additional features to assist users with database design tasks, such as data cleansing, data modeling suggestions, automatic data type detection, relationship exploration tools, and more. We should also consider, for every task, how the user might revert their actions or modify the database structure based on emerging or changing requirements.
Other Considerations¶
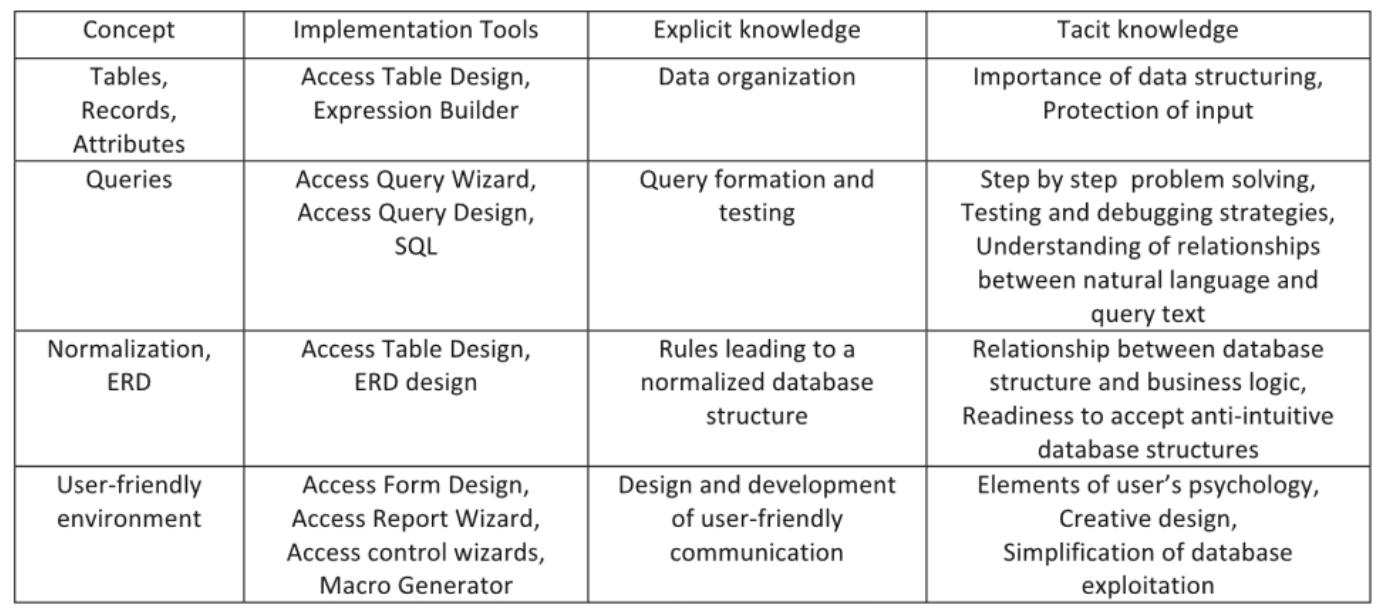
(Hvorecky, Drlik & Munk, 2010) stress the role of interface design in the acquisition of database querying skills. Their study identified the factors that influence how people learn to interact with data in a relational database and found that query interfaces based on natural language increased user’s satisfaction, accuracy and speed.
In another study, they identified the different concepts and knowledge required for appropriate learning of database management skills and proposed the following order for concept introduction: