Publicly shareable links¶
This spec describes the working principle of the initial versions of Publicly shareable links and ability to embed tables & explorations in other sites.
Goals¶
- Users should be able to publicly share tables & explorations as url links.
- Users should be able to embed tables and explorations in other sites.
What this feature is, and what its not¶
- This feature is related to publishing an existing table or exploration (and in the future, forms & queries) via public urls, which can be accessed by anybody with the link.
- This feature is not related to access control between users in a Mathesar instance.
Scope for the initial version¶
- The links will be generated only for tables and explorations.
- The links would display a read-only version of tables and explorations, i.e. only ‘viewer’ access.
- The links will not contain applied filters, groups, and sorting. If users want them, they can create explorations with the filters applied and then share them.
- The menu bar with options to filter, group, sort will be present.
- Inspector will not be visible in shared tables & explorations.
Assumptions¶
- Only users with manager access would want to share tables & explorations publicly.
- Embedding is assumed to take less work as the idea is only to provide code for an iframe with the public link. It may be removed from the initial verison as part of scope reduction if the work takes longer than anticipated.
Terminologies¶
- The names and terminologies used here are for the purposes of the spec only. It will differ during implementation.
- For implementation, we intend to name the feature ‘Shares’.
Suggested UX flow¶
User creating the link¶
Sharing a table/exploration:¶
- User opens table/query.
- Notices a button saying ‘Share’ in the table menu bar.
- This button is also present in the inspector.
- Upon clicking, the ‘Sharing control modal’ opens. Read further down for it’s UX.
When a table/exploration is already shared:¶
- User opens table/exploration.
- The button saying ‘Share’ in the menu bar & inspector have a different indication.
- This could be a different background or an icon.
- This indication would denote that the table/exploration is already publicly shared.
- Upon clicking, the ‘Sharing control modal’ opens. Read further down for it’s UX.
Sharing control modal:¶
- Modal shows information on whether the table is already shared or not.
- If shared, it shows the public link.
- Users can copy the link.
- Users can clear it.
- Users can regenerate the link.
- Users can see code to embed the table/exploration.
- Users can click on a hyperlink which opens the public link in a separate tab, so that they can preview it.
- If not shared, users can generate a new link.
User viewing shared link¶
- When users access the public url, they view the table/exploration in a dedicated page for it.
- This page will not contain breadcrumbs and profile controls.
- This page will contain the app header and the name of the table/exploration.
- It will contain a readonly view of the table/exploration, similar to how a ‘viewer’ would view it.
- It will not contain the table/exploration inspector for the initial version.
- Tables will contain the menu bar with options to filter, sort, and group.
Accessibility¶
- For the initial version, we will not support smaller screens.
High-level Backend implementation approach¶
Refer relevant discussions in mail thread.
Endpoints & DB schema:¶
Refer to Appendix #1 for approaches & discussions on selection of Django model structure. Refer to Appendix #2 for approaches & discussions on selection of API endpoint structure.
- Django models
- One abstract model containing common fields
- Each entity will have a model inheriting from the abstract model
- DB schema

- API endpoints:
- The
sharesendpoints will be placed within each entity. For tables, it would be: - CREATE:
POST /tables/<table_id>/shares/ - LIST:
GET /tables/<table_id>/shares/ - PARTIAL UPDATE:
PATCH /tables/<table_id>/shares/<link_id>/ - REGENERATE SLUG:
POST /tables/<table_id>/shares/<link_id>/regenerate/
- The
Authentication and Authorization for existing entity API endpoints:¶
- Bypassing authentication for APIs needed by frontend:
- For publicly shared content, we should be able to bypass login for the GET requests required to display the table/query in the UI. This includes GET endpoints in tables, queries, columns, records etc.,
- The frontend will set an additional request header
public_link_slugwhen attempting to access entity endpoints (eg., /tables, /queries etc.,) via a publicly shared url. The value of this request header will be the same as the slug of the public link.- Eg.,
public_link_slug:f2eea1b0-591f-4414-89ae-87d1688bf1d6
- Eg.,
- This can be done by adding custom permission classes to these specific endpoints, which override the default
rest_framework.permissions.IsAuthenticatedclass, and changes the condition to:- If isAuthenticated, provide access.
- If not authenticated, Check if the request contains the
public_link_slugheader. If no, reject request. - If
public_link_slugheader is present, Check if the relevant links table contains the slug. If no, reject request.- If the relevant table contains the slug, identify the entity the slug relates to. Check if the requested object (column, record, table etc.,) is either the same entity or a sub-entity of it. Eg., If a column is requested and the slug is linked to a table, check if the column is part of the table. If no, reject request.
- If yes, allow request.
- Bypassing authorization for APIs needed by frontend:
- The custom auth mentioned above would only be applied to GET methods of selected endpoints for actions like list, retrieve. Essentially, everything a viewer would have access to.
- Since the user is autonomous, we do not have to specify a custom
scope_querysetsince the access to the requested resource is public. - If the user is already logged in, we do not have to do any of this and let the existing logic take over.
High-level Frontend implementation approach¶
- Sending an additional request header:
- A request header
public_link_slugwill be sent will all API requests when the current parent route is/public/. The value of this header would be the same as the slug.
Appendix¶
1. Approaches & discussions on Django model and DB schema¶
Requirements:¶
- (1) When a table, query, or in future forms, charts etc., get deleted, the corresponding links should get deleted.
- (2) A link should contain metadata which is common to all kinds of links. Eg., password, access_levels etc.,
- (3) We might require entity specific metadata for links. For eg., Option to ‘Download as csv’ could be a table specific link metadata, or ‘Download image’ could be a chart specific link metadata.
- (4) We might require multiple links for the same entity. A table could have one link with access level as viewer, and another password protected one for access level editor.
Conditions:¶
- (5) Links are not top level entities i.e. We cannot have a ‘public_links’ database table and have mapping tables to individual entites. This is due to (1).
- When a table is deleted, there should not be an orphan link which we have to clean up with triggers.
- (6) It’s best not to rely on triggers and utilize FKs.
Things to consider while choosing approach:¶
- DB schema
- API request/response structure
- Complexity of backend implementation
Approaches that are not feasible:¶
- The “entity_type and entity_id polymorphic joins” approach.
- Does not satisfy (6)
- The “reverse-belongs to” approach where a table (or any entity) contains the link as part of it’s model.
- Requires dedicated mapping tables to implement (4)
- Duplications needed for (2)
- The “polymorphic django model libraries” approaches (Django polymorphic, Django model-utils Inheritance Manager, Django concrete inheritance).
- Does not satisfy (1) and (5)
Approaches considered:¶
Both the following approaches satisfy all points above.
‘Sparse table exclusive belongs-to’ approach.¶
- DB schema:
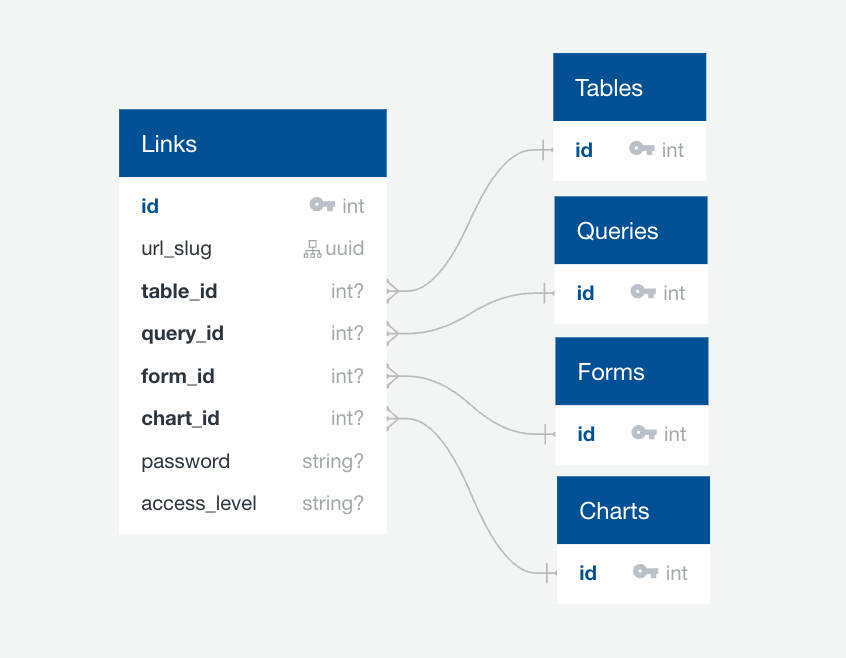
- DB schema when we implement (4):
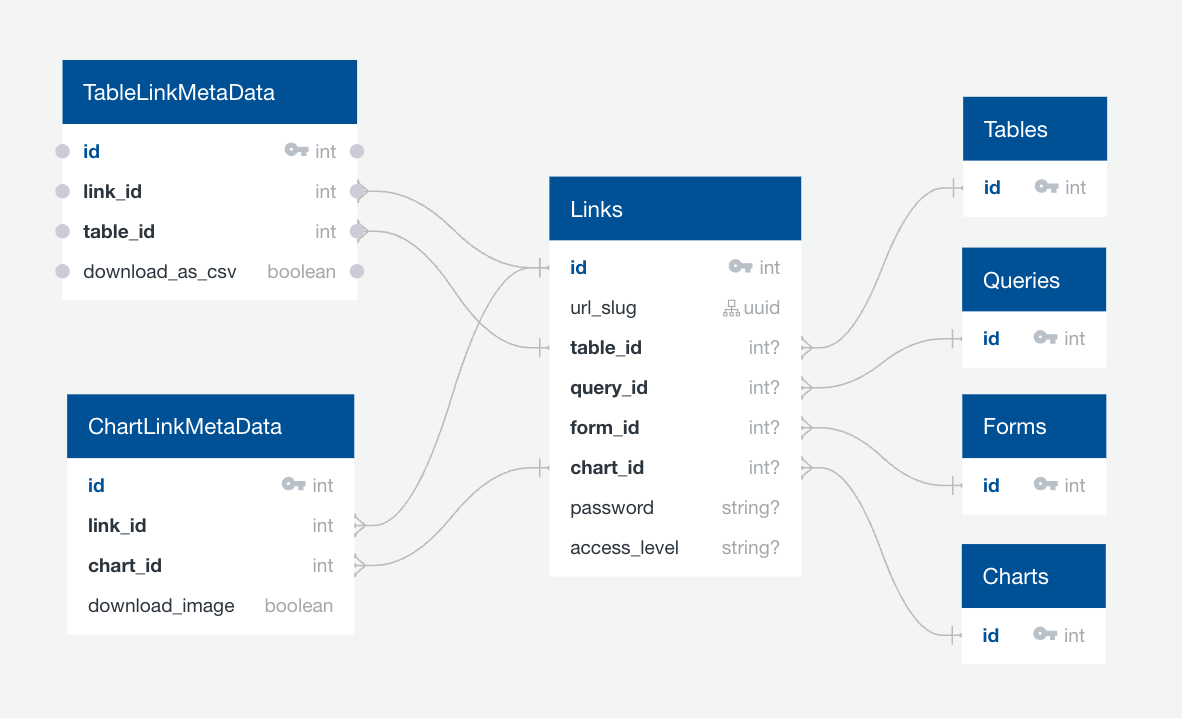
- Requires a check condition on the table to ensure that there’s exactly 1 of the entities for each link.
- Pros:
- API requests and responses would be under a single endpoint
/public_links/. - Public links can be generated as
/public/<url_slug>, without having to specify the type of entity in the url.
- API requests and responses would be under a single endpoint
- Cons:
- Simple for the initial version, but complexity increases when we have entity specific metadata.
- A multi-column FK would be needed in the metadata tables to ensure that the entity ids are not null.
- Queries would be fast but would require making joins to multiple metadata tables.
- Django models would get complicated.
- POST and GET API requests to
/public_linkswould have to include entity specify metadata:- Additional code would be required to update the metadata tables.
- Custom serializers might be required to parse the requests.
- We could attempt to simplify this portion using the Django polymorphic libraries, but it introduces the complexity of adding and utilizing another library.
‘One dedicated table per entity’ approach¶
- DB schema
- Pros:
- Models are simple.
- Can be implemented using abstract models, and Django simplifies all implementation logic.
- API requests & responses don’t require custom handling.
- Queries would be fast.
- Each entity’s custom metadata would be part of it’s own table.
- Cons:
- Multiple tables with similar duplicated columns would be required for a feature which is essentially common to all the entities.
- API requests & responses require multiple endpoints, one for each entity.
- Tables would be under
/public_links/tables/ - Queries would be under
/public_links/queries. - Public links would need to contain the type of entity.
- Tables would be shared with link
/public/tables/<url_slug>. - Queries:
/public/queries/<url_slug>.
Recommendation¶
- Implementation and maintenance wise, the ‘One dedicated table per entity’ is the simplest, and considering that we might definitely have entity specific metadata, I’m recommending it.
- I don’t see an issue with having the entity in the url (eg.,
/public/queries/<url_slug>). - Anything we might want to do with links would require us to do it in all the tables, but Django simplifies that for us, so I don’t see complexity there.
Result¶
- It was discussed and concluded via mail that we’ll go ahead with the ‘One dedicated table per entity’ approach.
2. Approaches on API endpoints¶
Option 1:¶
CREATE: POST /shares/table-link/. Table id will be part of request body.
LIST: GET /shares/table-link/
LIST & FILTER BY ENTITY: GET /shares/table-link/?table=<table_id>
LIST & FILTER BY SLUG: GET /shares/table-link/?slug=<slug>
PARTIAL UPDATE: PATCH /shares/table-link/<link_id>/. Table id should not be allowed to be updated.
REGENERATE SLUG: POST /shares/table-link/<link_id>/regenerate/
Pros:
- Shared url need not contain entity id:
http://localhost:8000/shared/tables/<slug>/ - Code related to shared links can be within a single place
- Generic viewsets and serializers can be written reducing possible duplication
Cons:
- Entity id needs to specified as part of request body.
- Additional logic would be required to disallow update of entity id.
- Additional logic required to filter by entity id.
Option 2¶
Endpoints for shares would be placed within each entity. For table, it would be:
CREATE: POST /tables/<table_id>/shares/
LIST: GET /tables/<table_id>/shares/
LIST & FILTER BY ENTITY: (This is the same as list)
GET /tables/<table_id>/shares/LIST & FILTER BY SLUG: (Not required by frontend, since shared url already has GET /tables/<table_id>/shares/?slug=<slug>table_id)
PARTIAL UPDATE: PATCH /tables/<table_id>/shares/<link_id>/
REGENERATE SLUG: POST /tables/<table_id>/shares/<link_id>/regenerate/
Pros:
- Placed within hierarchy of respective entities
- Entity id is a path param:
- Entity need not be specified in the request body additionally
- No additional filtering needed by entity
- Update requests should not modify entity, and since entity is part of url path, no additional logic is needed for it
- Option to filter by slug is not required
Cons:
- Shared url needs to contain entity id:
http://localhost:8000/shared/tables/<table_id>/?token={$slug} - Some code duplication might be needed
Result:¶
- Pavish and Kriti discussed via private chat and decided to go with Option 2.
3. Scheduled for later iterations¶
- Shared views with persisted filters, grouping etc.,
- Option to restrict link access by password
- Sharing record page & forms
- Option to share as editor
- Option to show table/exploration inspector
4. Competitive research¶
Airtable¶
- Option to generate link & embedding view is present in menu bar.
- Shared views are read-only.
- Option to share entire bases.
- Links:
- Once link is generated, there are options to clear it, generate new link.
- Options to restrict/allow users to copy data from view. Options to restrict/show all fields, including ones created in future.
- Option to restict by password or by email domain (needs higher plan).
- Embed:
- Provides code to embed iframe.
- Shows desktop and mobile preview.
- Option to show/hide controls bar.
- Filters, groups, and sorting added to a table is applied to the shared output view.
- This is possible because this configuration is always persisted.
- Option to share form for cases where adding data is required.
NocoDB¶
- Link is automatically generated for all tables.
- Option to restrict access via a password.
- Option to restrict/allow download.
- Filters, hidden columns, sorting etc., are automatically applied to shared link.
- This is possible because this configuration is always persisted.
- Shared content is read-only.
Google sheets¶
- Option to share content as viewer, commenter, and editor.
- Option to publish a public url which does not require users to login to view the content.