August 2022 meeting notes¶
2022-08-31 weekly meeting¶
- Topic: New proposal for backend architecture, see Brent’s email + implementation plan.
- Participants: Mukesh, Dom, Brent, Kriti, Sean, Pavish
We discussed Brent’s proposed architecture. Everyone is on board with the plan. Items discussed:
- Would exposing OIDs and attnums directly in the API cause security issues?
- Potentially, since OIDs are smallints and roll over, but attack potential seems low-risk.
- The backend simplication is worth it.
- Trivial to fix by encrypting database identifiers.
- We will probably need some combination of Django / DRF permissions and database roles, even if we do most of the work in the database.
- This is so that we can unify permissions for Mathesar-specific objects like Explorations
- This isn’t a panacea, there will probably be complications while refactoring and we’ll probably have a whole new set of problems later
- But it’ll be good to have new problems instead of these ones
- psycopg3 has async capabilities and prepared queries, could be used for better performance in the future
We also discussed backend performance fixes:
- Global metadata should make a huge difference in performance (we anticipate 5 sec API calls going down to 1 sec)
- Pre-fetching data in APIs should make a significant difference as well (1 sec to 200 ms)
- We’d like to do both of thse before we can do a live demo of Mathesar
We don’t want to “go backwards” too much from our planned architecture, but we’ll make the following exceptions:
- Backend performance fixes, since the live demo is necessary for product goals
- Implementing users and permission without using DB roles – only database and schema level permissions to keep things as simple as possible.
In terms of implementation, we need to get everything for Cycles 4 and 5 done before we can start on the refactor proposed by Brent. This includes:
- the performances fixes above
- Users & Permissions
- Mathesar installation issues (upgrading Mathesar, easily installing it)
- Backend needed for sharing feature
Once we’re done with these, any available backend engineers can start incrementally implementing the refactor. We’ll plan this out further when we get to it.
Next steps for now are that Mukesh and Dom will meet and divide up the backend performance work between them. Brent will start on Users & Permissions work.
2022-08-30 Cycle 4 planning¶
Attendees: Brent, Dominykas, Ghislaine, Kriti, Pavish, Sean, Mukesh, Rajat
Retrospective¶
- Please see this FigJam file (only accessible to core team)
- Lots of things went well, more than last time. Some common sentiments:
- Communication patterns are better
- Spec process is smoother
- Feature spreadsheet is great
- Progress on difficult features
- Targeted assignments are working well, less noise
- Things that could have been better (highlights):
- The spreadsheet didn’t track all work, excluded some progress from seeming meaningful
- Mukesh and Dom on frontend seems like a bad use of time/resources
- Backend and frontend both need to spend time on testing, refactoring, etc.
- No-one specifically assigned to the “global view” of the demo working
Please see the FigJam for all the notes.
Cycle 4 plan¶
We went over the items in the Cycle 4 spreadsheet to:
- Discuss all the items planned for Cycle 4
- Update progress
- Update or make assignments
We now have specific items and assignees for things like:
- Demo Video Readiness
- Mathesar Website
- Live Demo Readiness (covers all UX issues and completing features)
“UX Design” work is now “Planning & UX Design” and encompasses coming up with a list of deliverables and other planning work.
Mostly the list looks fine. API & DB performance items are tentative and will be broken down into more detailed pieces after tomorrow’s weekly meeting.
Everyone had enough work except for Brent (now assigned to Users & Permissions) and Pavish (now assigned to Demo Video Readiness).
We will triage the issues in the Cycle 4 milestone on GitHub when we get to the planning phase of “Live Demo Readiness”.
Workflow changes¶
Our workflow will mostly remain the same.
- We’ll continue to have weekly meetings, although we’ll try to make them shorter and more relevant for everyone.
- We’ll maintain a document for things to talk about in the next cooldown period so that we don’t distract ourselves with non-urgent or irrelevant conversation during the cycle.
Other issues from the retrospective should be addressed by:
- Having explicit items in the work tracking spreadsheet to cover marketing and other work (all work should be covered in the spreadsheet)
- Assigning specific people to “global view” tasks like making sure everything needed for the demo video is in place
- Deciding on the backend architecture we’re aiming for and fitting new work into it.
- Thinking of the Cycle 4 spreadsheet as a prioritized list, not as a set of goals that we have to get to 100% on everything.
- Figuring out next steps for performance and testing issues, which are explicitly tracked on the spreadsheet.
2022-08-30 Front end team¶
Imperative upwards data flow from input components¶
- Sean would like to standardize a pattern for input components to use events or props to inform their parent of changes to their value.
- Decision: For consistency, all our input components will dispatch
artificialInputandartificialChangeevents. This pattern will allow consuming components to listen only to those events in order to access the input’s value directly (within thedetailproperty of the event). - Next steps: Sean will create a ticket for this.
Separating layout CSS from aesthetics CSS¶
- Rajat would like to to encapsulate layout CSS properties like display, padding, and margin in re-usable component.
- I propose the following component: Stack. This can be used to stack things on top of each other or next to each other.
<Stack gutter={15} direction="vertical" gap={15}>{children}</Stack>. - This will provide the following benefits:
- Less CSS footprint.
- Standard way of creating space between the elements.
- Less clutter for the designer to do asthetic CSS changes.
- One can also read the layout while reading the code without referring to CSS classes again and again.
- Easier review of the layout CSS during PR reviews.
- Increased development speed
- Detailed explanation of this idea can be found here: https://every-layout.dev/layouts/stack/.
- Decision: We’ll give this a try incrementally.
- Next steps: Rajat will create the component(s).
Testing¶
- Pavish wants more test coverage for front end to prevent regressions.
- We all discussed various strategies.
- We will try to write more unit tests for components using Testing Library. We will use the ‘msw/node’ package to mock API data when needed. Example.
- We will also explore the possibility of using Playwright from node with mocked data to perform higher-level tests against the whole app.
New coding standards proposed¶
- Sean has proposed two new coding standards.
- Prefer
awaitover.thenwhen possible - Prefer
functionoverconst
- Prefer
- Decision: Approved. Sean merged the PR.
2022-08-24 Cycle 3 check-in¶
Attendees: Brent, Dominykas, Ghislaine, Kriti, Pavish, Sean, Mukesh, Dhruvi
Cycle 3 progress¶
- Data Explorer (backend 100%, frontend very close)
- Column extraction (backend 100%, frontend 20%)
- Record summary (backend 90% frontend 70%)
- Record selector (backend 100%, frontend 95%)
- Record page (backend 100%, frontend 40%)
- Grouping (backend 98%, frontend 100%)
- Filtering (backend 100%, frontend 100%)
- Data Import (Design is in progress, frontend should be quick to implement)
- Styling (frontend 15%)
- Schema page (0, 0, but Ghislaine has started work)
Work assignment changes¶
- Consider changing owner of record summary feature from Mukesh to Sean
- Sean and Mukesh will decide on this after a meeting later today
Plan for Cycle 4¶
- Once we get to 100% on all the required features, we will go through the demo and find UX issues that are blocking it
- Hopefully Thursday or Friday next week
- We’ll prioritize those issues for Cycle 4
- Cycle 4 will also handle performance issues, including better handling of SQLAlchemy metadata and performant reflection
Back end meeting 2022-08-15¶
Attendees: Brent, Dominykas, Mukesh
We realized that there’s a real feeling of time crunch that makes Dom reluctant to request code review, and all of us reluctant to spend enough time on doing the review for large PRs, or even moderately-sized ones. Turnaround is quite slow due to TZs, and even getting a fairly easy PR merged can take multiple days, which is a problem in our current situation. This is why Brent is going to push for sync review when when he feels his willingness to spend the time on it waning. It will be a time-saver in the long run that way.
Dom thinks we should stick with having the author decide whether PR will be reviewed or not. Brent agrees, but thinks we should be more pro-review that previously.
Mukesh advocates for TDD. He thinks that it tends to lead to smaller PRs, since you end up (usually) with checkpoints where you can merge. Might be worth considering for those advantages, but can also be constraining.
Idea: use TODOs to avoid getting sucked into larger projects, and also to avoid breaking flow to create issues.
Dom’s action items:
- Create TODO comments in code as working, collect into issues at a later time.
Brent’s action items:
- set up sync call when noticing demoralization while reviewing
- Also use TODO comments
Mukesh’s action items:
- Continue using TDD, help others understand where it’s most useful.
2022-08-10 Cycle 3 check-in¶
Attendees: Brent, Dominykas, Ghislaine, Kriti, Pavish, Rajat, Sean, Mukesh
Cycle 3 progress¶
We made progress on the following:
- Data Explorer (backend and frontend both over 90%)
- Navigation (design finalized, implementation almost complete)
- Table Inspector (design almost finalized, implementation starting soon)
- Record Summary (backend at 85%)
- Record Selector (frontend at 85%)
- Filtering (design finalized, implementation in progress)
- Data Import (design in progress)
- Styling (Ghislaine has started work)
- Data Modeling Suggestions (requirements worked out)
- Dynamic Defaults (requirements and backend plan worked out)
Work assignment changes¶
- Mukesh assigned to Column Extraction front end
- Dom will switch to frontend issues after Sean finishes Navigation
- Brent will focus on general backend support for Cycle 3 and take over any work from Dom or Mukesh as needed
- Dhruvi may need extra work, we’ll figure that out during the week since she’s not here today
Collaboration needed¶
- Data Explorer
- Brent and Dom will meet to discuss bug
- Table Inspector
- Ghislaine, Kriti, Sean, Rajat, Pavish will meet to resolve open questions
- Styling
- Ghislaine, Sean, Rajat, Pavish to meet tomorrow once Ghislaine has her branch ready
- The goal is to discuss how to structure CSS in our codebase
- Column Extraction
- Spec should be ready by Friday to unblock Mukesh
Cycle 3 extension¶
We decided to extend Cycle 3 by 1 week to Aug 26. Since Record Page and Data Import are still at 0% and won’t be started until the end of the next week at the earliest, giving ourselves another week should get us much closer to completing our work.
This is a one-time extension, Cycle 3 will definitely end on Aug 26.
2022-08-05 Dynamic Defaults¶
Topic: Backend planning for Dynamic Defaults feature
Attendees: Dominykas, Brent, Kriti
-
First steps:
- Create a Django Column DD field that holds a DBFunction
- Have it define Postgres column’s DD
-
Dominykas’ plan:
- Store dynamic default (DD) in Column Django model
- as a DBFunction
- Make sure frontend knows whether default is static or dynamic
- Don’t declare which DBFunctions are good as DDs
- for the sake of implementation speed
- Hardcode DBFunctions to use on the frontend
- for the sake of implementation speed
- Don’t reflect third-party defaults, only defaults created in Mathesar
- to be clear, we can reflect an SQL always
- it’s just that we can’t offer a nice UX for third-party DDs
- Once we want to provide “non-malicious tampering” guarantees (in the future)
- meaning guarantee that a third-party has not accidentally messed with it
- we can wrap the DD SQL expression in a special SQL function that
- has an argument holding the JSON for the DBFunction
- has an argument holding the SQL expression for the DBFunction
- Extend table columns endpoint’s “default” sub-dict
- to describe whether it’s a first- or third-party DD
- Store dynamic default (DD) in Column Django model
- For Cycle 3:
- Implementing the plan, but not tampering guarantees
- Making tickets for tampering guarantees
- After Cycle 3
- Implement tampering guarantees
- Extend the system to handle more types of defaults and sequences
- e.g. ID column sequences
- Could be good first-time contributor tickets once infrastructure is set up
-
Caveats:
- Dynamic defaults likely won’t reflect in the same form as created
- Some are created as python functions, reflected as string
- Could be optimized in unclear ways
- Dynamic defaults likely won’t reflect in the same form as created
-
Current blob:
GET http://localhost:8000/api/db/v0/tables/2/columns/ ... { "id": 7, "name": "id", "type": "integer", "type_options": null, "display_options": null, "nullable": false, "primary_key": true, "valid_target_types": null, "default": { "value": "nextval('\"Library Management\".\"Publishers_id_seq\"'::regclass)", "is_dynamic": true } }, ...
Needed tickets¶
- Guarantee wrapper
- showing non-dynamic, dynamic (Mathesar), dynamic (3rd-party) for API
Reference: Dynamic Defaults Proto-Spec¶
Problem¶
We are considering implementing Dynamic Defaults as it increases the usability of adding new records.
For the purposes of the demo we need the following defaults
- Current date and time
NOW()
- Current date and time + a specific duration (e.g. 14 days)
NOW() + '2 weeks'::INTERVAL
The dynamic default options will depend on the field’s data type.
We should consider implementing dynamic defaults using the same formulas that we plan to implement in the future
Proposed User Flow¶
- User selects a column
- The inspector panel displays the properties for that column
- User toggles the “Default Value” option
- The user selects from a list of preset options
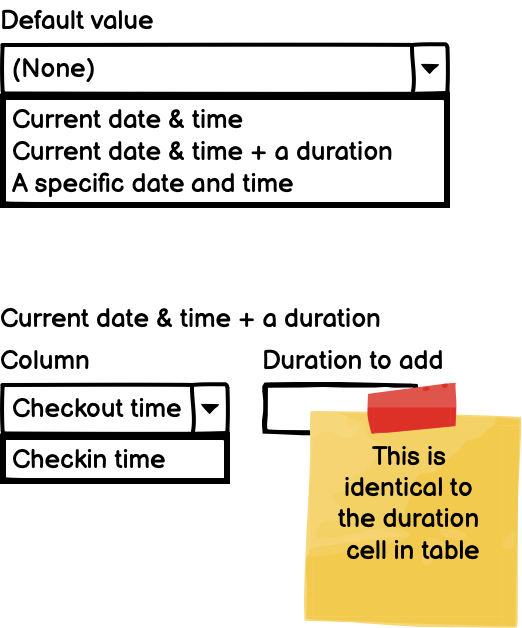
Formulas to use from our Formulas
- Current date and time: “Current date & time” formula
- Current date and time + duration: “Add Duration to Date” formula
- A specific date and time: static default (not dynamic)
- show date time picker
2022-08-04 Data Modeling & Schemas¶
Topic: Resolve product and design questions for Brent’s upcoming work
Attendees: Kriti, Ghislaine, Brent
Data modeling suggestions¶
“Suggest Candidate Columns to Create Separate Table” internship report
Questions¶
- Better to extract too few columns or too many?
- How fiddly should the feedback loop of deciding which columns to extract be?
- Brent’s proposed process:
- Suggest set of columns to extract
- Explain to user why those are useful
- User adds or removes columns
- Analyze in second round
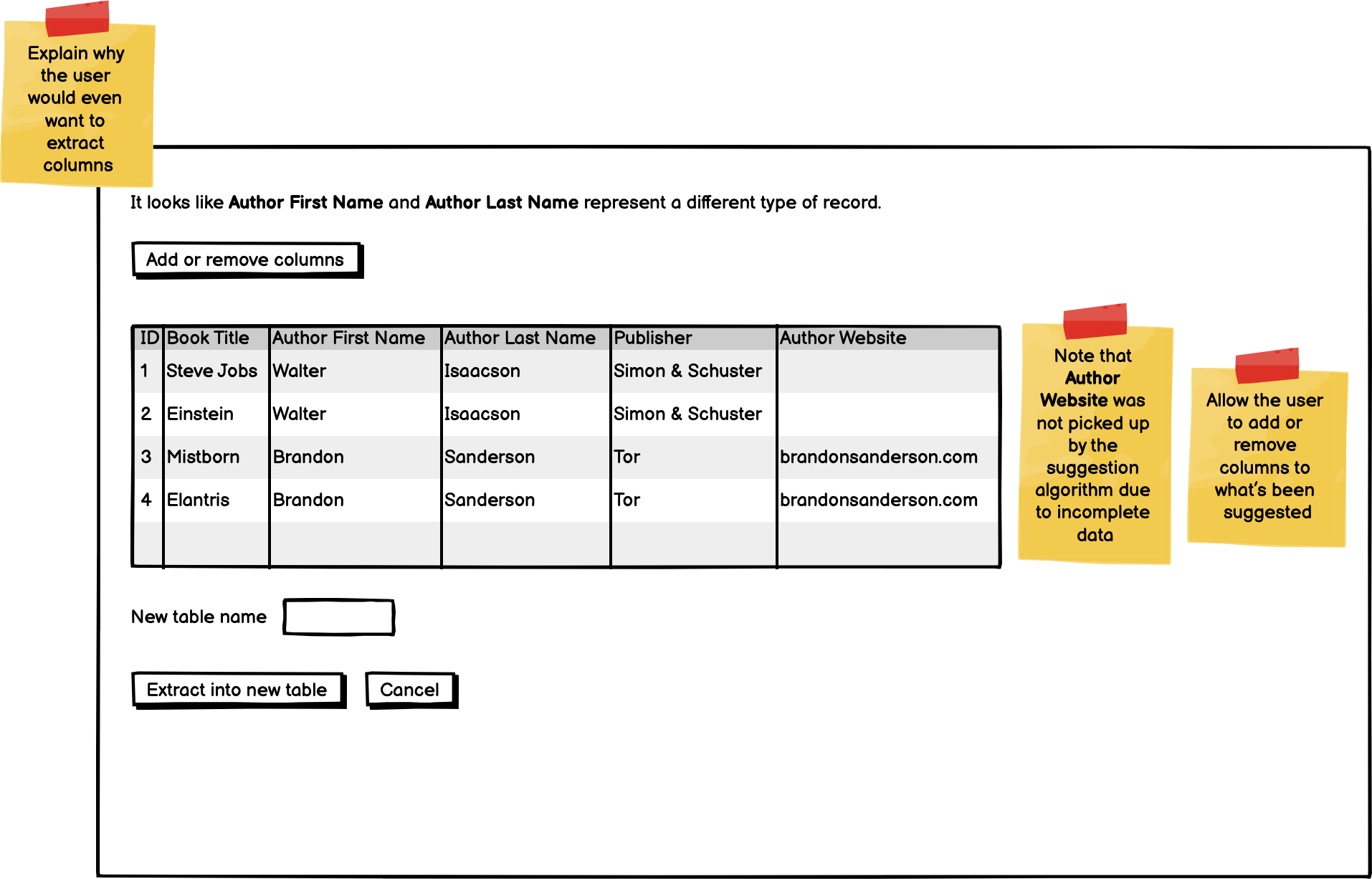
- Alternate process (more manual):
- Have the user guide more of the column extraction
Discussion¶
- Brent’s first proposed process is preferable from a UX perspective, having the user make repeated decisions is not ideal
- Second round is not necessary, let’s stick to one round.
- It’s better to be conservative with suggestions, better to suggest fewer columns than potentially unrelated data
- Eventually explore ProbComp integration
- Number / Date & Time (non-categorical data) should be avoided during suggestions, since it’s too risky and will involve additional statistical analysis to get right
- Not even if they’re directly correlated to categorical data columns (e.g. if there’s a person’s name and birthday, we only suggest name, not birthday)
- Brent will check for easy wins if there’s not too much effort involved
Schema homepage¶
- Schemas will now have descriptions, stored in DB comments
- Mathesar won’t own the description, other clients can edit it
- UX should make it clear that this data can be edited outside of Mathesar (maybe mention that it’s stored as a DB comment)
- We should also do this for tables and columns at the same time, since it’s a very similar implementation
- We can easily get the count for both Mathesar-specific data like Explorations and for DB objects
- We can be more precise with DB objects
2022-08-04 Table Inspector meeting¶
Topic: Resolve major questions remaining before finalizing the table inspector spec
Attendees: Ghislaine, Kriti, Sean, Rajat
Spec Overview¶
We took a quick look at the current spec and content.
Selection Modes¶
- Do we agree or have any concerns with the proposed selection modes?
- Selection triggers might not be the best way to trigger inspector modes.
- A tabbed panel that groups properties by level (table, column, record, cell) might be better.
- Column and Row information will be derived from selected cells.
- The selection status would change based on active tab

- Are we planning to provide keyboard and touch device interactions for selections in this cycle?
- No
Contextual Menus and Inspector Interactions¶
- Will the user be able to trigger the inspector panel via contextual menu actions?
- Yes, but will not be part of Cycle 3.
- We discussed the concept of adding an option like “Show Column Properties” in the inspector to open it with a chosen tab.
- Do we need to incorporate contextual menu actions into the spec?
- Not for this cycle.
We want to do this, but not in Cycle 3.
Defining Actions and the Actions Panel¶
- Do we agree with the proposed use of actions to represent data transformation or modeling tasks?
- Yes, we agreed
- We need to make sure actions are consistent, e.g. Set to NULL is probably a property because it’s related to the cell value
Ways to Enable Inspector¶
- Do we agree or have any concerns with the proposed inspector states and triggers?
- Not selection triggered
- User can toggle
Decisions¶
Out of Scope (for this spec / Cycle 3)
- Context menu changes for opening the inspector
- Keyboard and touch interactions
- Selecting disjoint cells and columns (will defer to keyboard interactions)
Reference¶
Sean’s proposed “Cell-only selection”¶
For the sake of brainstorming, I present a rough design which unifies the selection behavior for cells, rows, and columns. I’m not attached to this design, but rather putting it forward to demonstrate an alternate approach that may lead to even better design ideas collaboratively.
- Cells can be selected – but rows and columns cannot.
- Multiple cells can be selected via the same UX as LibreOffice Calc. Clicking on a row/column header selects all the cells within the row/column.
- As with LibreOffice Calc, the row/column headers visually indicate which rows and columns contain the current selection.
- When at least one cell is selected, an “Actions” sidebar appears on the right.
- The Actions sidebar can be hidden and re-shown by clicking on arrows. Its visibility state persists in local storage.
- If the actions sidebar is hidden, then all cells have a context menu which shows the contents of the actions sidebar. Opening the context menu from a selected cell maintains the current selection. Opening the context menu from an un-selected cell changes the selection to contain only that cell.
- The actions sidebar contains collapsible sections for “Cells”, “Rows”, and “Columns”. Each section heading also displays the number of entities currently selected, e.g. “Cells (3)”.
- The “Cells” section contains actions like “Set to NULL”, “Set to DEFAULT”, “Set to Now”, “Copy Down”, “Copy”, “Paste” and other actions depending on type.
- The “Rows” section contains actions like “Delete”, “Duplicate”
- The “Columns” section contains all the UI currently in the column header menu, plus the new UI for extracting columns.
- To aid in the discoverability and usability of selecting multiple cells in nonadjacent blocks, the Actions sidebar also contains a button labelled “Grow Selection” which displays above the Cell/Row/Column sections. When the user clicks “Grow Selection”, the button visually pulses indicating that a special (and persistent) mode has been enabled, and the user can select cells as they would with
Ctrlpressed in LibreOffice Calc. A help message also displays below the button when grow-selection mode is enabled.
2022-08-03 Cycle 3 check-in¶
Check in on everyone’s work¶
Brent¶
- Was blocked on summarization until today, unblocked now
- Made progress on setting up library dataset, pretty much done
- Not sure if it works on Windows, but that’s not relevant for Cycle 3
- Reviewed Maria’s work for Data Modeling Suggestions
- Meeting with Kriti & Ghislaine tomorrow to discuss product work
- Schema homepage on backburner since it’s quick
Dhruvi¶
- Data Import work is moving along
- Deliverable will be a spec
Dominykas¶
- Filtering almost done, need to meet with Pavish
- Will be scheduled soon
- Dynamic Defaults
- Thinking about implementation constraints
- Will meet with Kriti and/or Ghislaine to discuss product concerns this week
Ghislaine¶
- Navigation spec should be merged today
- Table Inspector
- Draft of spec ready
- Need to meet with Rajat and Sean about deliverable
- Column Extraction
- depends on table inspector, will need separate spec
- Schema Page
- not yet started
- Styling
- not yet started, hopefully this week
Mukesh¶
- Column Extraction pretty much done, awaiting final review from Brent
- Record Summary backend work is close as well
- Record Summary frontend work is not yet started, will take up the rest of the week
Pavish¶
- Data Explorer will occupy time until next meeting, including Filtering
- Grouping & summarization in Data Explorer are next
- Data Import has not been started
Rajat¶
- Currently working on introductory tasks, making progress
- Next task: Table Inspector
- Read spec
- Meet with Ghislaine & Sean
Sean¶
- Need to resolve Navigation work assignment (see next agenda item)
- Record Selector work is moving along
- Record Page has not been started yet, would be good to do after Navigation
Navigation work¶
Difficult for Sean to coordinate with Pavish due to TZs. Navigation work seems to involve fiddly modifications of lots of code that Pavish originally wrote, thus it would be quicker with coordination.
Options¶
- Sean and Pavish find a better meeting time (difficult)
- Pavish takes navigation, give some work to Sean in return
Decision¶
- Sean and Pavish will meet and discuss in a separate call
Renaming Queries to Explorations in the UI¶
Thumbs up all around
Data Import work¶
- Design constraint:
- We want to make sure that the user understands that they cannot navigate away from the page during the import process.
- A modal is one way to do this, but it’s just a suggestion
- It will significantly simplify code on the frontend if we can stop portraying import as asynchronous like we’ve been doing
- We discussed rethinking the import flow to allow the user to having more stopping points in the import process since it’s synchronous
- they can see the files they’ve uploaded
- they can decide to import a specific file into a table
- they can control the inference process and whether/when it happens
- We decided not to rethink the flow since it complicates Cycle 3 work and is irrelevant to our use case.
- We will need to update the import flow to account for importing data into existing tables (Anish’s work), so we can think through all this then.