May 2021 meeting notes¶
2021-05-25¶
Welcome Eamon!¶
- Eamon started yesterday
- Introductions all around
- Nice work on link-rot issue!
New Design Review channel¶
#design-review:matrix.mathesar.org- for design review (like code review)
- Review process:
- Required reviewers: Kriti, Pavish
- Brent & Eamon are strongly encouraged to review
- Process:
- Document shared in the channel
- Reviewers should comment on the document
- Pay attention to missing components
- Ask questions about how to implement something
- Raise limitations if any
- Comment in the channel when you’re done reviewing
- Ghislaine will resolve comments and post in the channel if it’s ready for re-review
- Once it’s done being reviewed, Ghislaine will summarize decisions made in comments
- Then it will go to the wiki as ready for implementation
- Ghislaine will summarize above process on the wiki
- Please prioritize reviews, like any other work that blocks people
Design / Development Process follow up¶
- Goal is for design to be two features ahead of development
- There should always be three features (let’s call them A, B, and C) in progress:
- A is being implemented
- B is in design review / discussion / technical spec
- C is being designed
- There should always be three features (let’s call them A, B, and C) in progress:
- Concerns raised about too much parallelization and splitting effort too much.
- Sometimes it’s better to go slower and ensure we’re on the same page.
- A, B, C are separate types of work, so shouldn’t conflict.
- Let’s try it!
Standups¶
- Linking to issues and PRs in your standup is encouraged, but please describe them in addition so that people can get context without have to click through
Typescript port¶
- GH discussion is open: https://github.com/centerofci/mathesar/discussions/145
- We could have a brief discussion on call if the team has not yet gone through the GH discussion
- Concern about how many people know Typescript, is it contributor friendly?
- (Lots)
Retrospective¶
Kriti¶
- Set up Matrix bot
- File import API (including schema creation API and overhaul of file storage and copying)
- Various discussions
Pavish¶
Did not have enough time to work during weekdays. Not as productive as I hoped.
- Built Tab and Tree Components
- Ported code to TypeScript
Brent¶
- Finished PRs to implement custom logic for casting between types
- Finished PRs to use that casting in type inference algorithm
- Finished PRs to use type inference algorithm to determine types for table columns
- Finished PR to implement getting records in given order (by columns)
- Submitted PR to allow getting valid grouping filters, then filtering table by them to create groups of records.
- Started / contributed to discussions about types, lossy type conversions, and assumptions about user roles.
Ghislaine¶
- Worked on prototype for ‘Add new table from file import’
- We had a design review and changes were implemented
- Documentation updates to inventory use case
- Had to update my knowledge on figma prototyping
Active work plan¶
Implementation: Read only tables Review/Prep: CSV import Design: Filtering, sorting, grouping & Pagination
Next: Editing tables
Kriti¶
- Document general implementation principles for API
- Finish up file import API work, including table creation from file import.
- Work on TSV file imports with Joi
- Additional API work as needed to support the file import frontend
I have more communication training and interviews this week, so I don’t have as much time.
Pavish¶
- Define clear route boundaries on client for table view and import
- Switch to new api for import
- Maintain open tab and tables state in url
I will have only about an hour during the weekdays, this week and next. Will have to defer dev work to the weekend. I don’t think this week will be productive for me.
Next week - on call, may have to drop out during meeting.
Brent¶
- Finish up current PR review process (regarding filtering)
- Kriti: I merged this already
- Work on syncing objects between data DB and models (webapp)
- Catch up with Eamon about endpoints for functions
- Maybe help with API work
Ghislaine¶
- Work on pagination update for read-only tables
- Update design process for reviews and definition of done
- Start work on design for filtering, sorting and grouping of table data
Eamon¶
- Download image automation
- Meet with Brent about endpoints
- Start endpoints work
Upcoming work for backend¶
- We have three people on the backend currently, so we’ll need to get ahead of frontend a little bit for the next few weeks
- Next issue for whoever is free on the backend first: https://github.com/centerofci/mathesar/issues/69
- Other backend issue: come up with install instructions for Mathesar
2021-05-21¶
Meetings starting next week¶
- Fewer meetings starting next week
- Meetings so far are frequent, we are relying too much on synchronous discussion
- Async discussions are better, we can think about things more, and it’s documented
- Design reviews - it’s still useful to have those synchronously
- We can schedule additional synchronous meetings as needed ad-hoc
- Only Tuesdays starting next week
- Will also give us more uninterrupted time
- Team events after Pavish starts full time for team building
Eamon starting Monday¶
- New Summer intern
- He’ll be in meetings, research sync, LWT, etc.
- We’ll treat him as a member of the team
- Kriti will schedule call on Monday
- First task: GH Actions
- Automation will be useful for us, good for learning
- Detecting link rot
- Moving images uploaded via HackMD to wiki
- Second task:
- API endpoints for filtering/ordering/grouping
- He’ll be working with us for 3 months
- We’ll need to make sure meeting times work
2021-05-19¶
Import from file user flow¶
(Ghislaine demoed wireframes on Figma)
Remote URL vs. Local file upload¶
How wiki.js shows it:
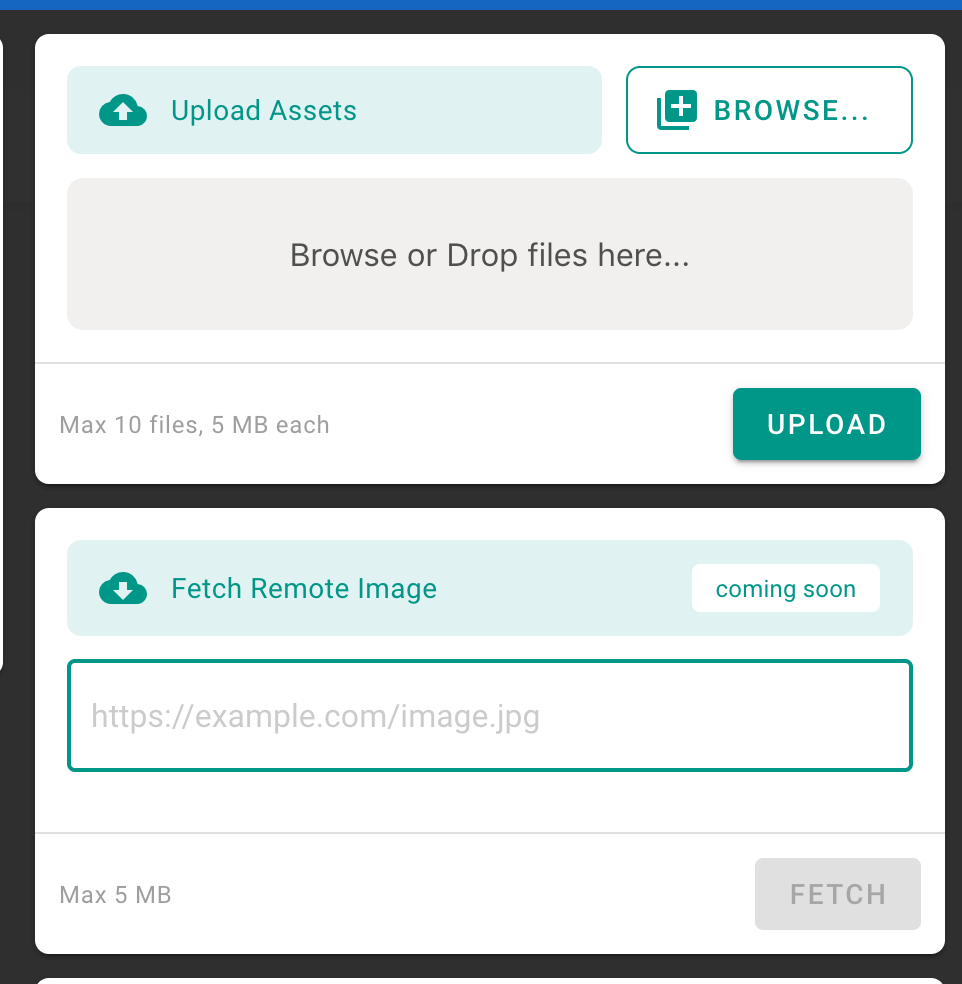
Feedback¶
- “Import Data” panel
- need to show a file uploading / loading indicator in “Import Data” step
- we need to ask user whether to consider first row as header
- checkbox with default checked
- “Map Columns” panel
- we can select columns that should not be imported
- dropdowns should be changed to an interface that shows they can edit freely
- “Review Data” panel
- only show first few rows of data (but show total count)
- This shouldn’t be a modal
- Should be its own dedicated page
- Might take a while, dedicated page could show status of the upload and not block user.
- Sidebar under “tables” with a loading icon?
-
- Cannot allow user to close browser window because upload won’t work, so hiding it in the sidebar is not a good idea, show something prominent
-
- Status bar on the bottom might show current operations at the bottom, like chat windows
- Make it very clear that the window shouldn’t be closed
- Needs explanatory text / guiding user through steps and adding confirmations
Discussion about combining views¶
Screenshot from Dabble DB
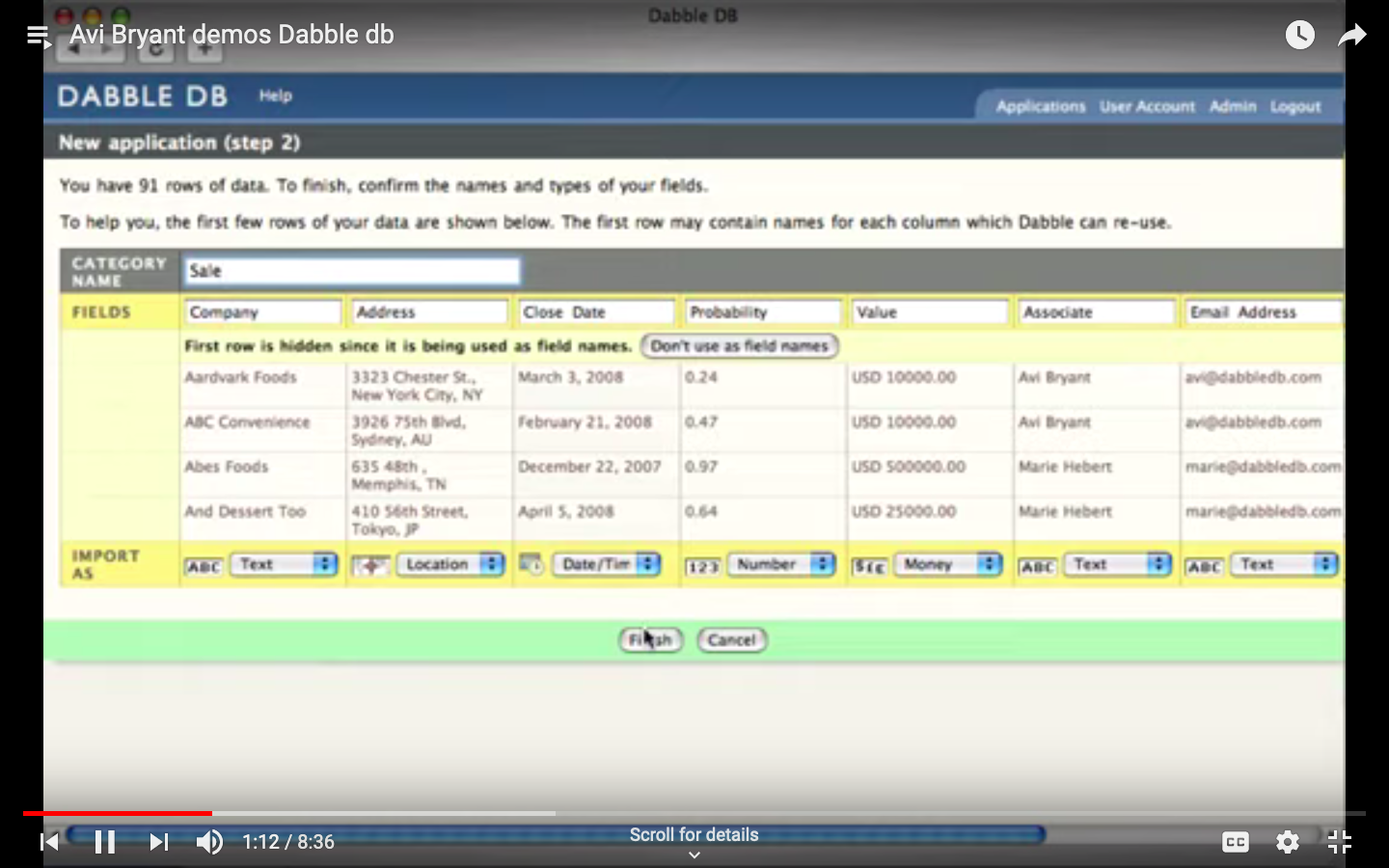
- Combining all three views puts everything in one place.
- Might lead to horizontal scrolling if there are a lot of columns
- Need a default name for the table
- Can use the filename (maybe filename + timestamp)
- Once they click on the table, it takes them to the DabbleDB kind of view for the table
- Sidebar should have separate icon for this
New design components needed¶
- System notifications
- Progress bar and errors
Roadmap updates¶
- Roadmap should help us define the basic product functionality
- We should stop some product definition work before we have the MVP
- Let’s focus on basic features first before building hairy features
- We’ll hold type inference at the current stage (after finishing #93)
- We’ll try to get DB client features first
- Upload
- Edit
- View
- filtering
- ordering
- grouping
- Installation
- Multiple Databases
Paginated view vs. Infinite scrolling¶
- Paginated might support the interactions we require for editing records.
- We won’t aim to have a full spreadsheet-ui experience
- We’ll only support spreadsheet like operations on visible records
- Let’s see how far we get with pagination
- We can consider full spreadsheet like capability using HTML canvas in the future
- We’ll avoid having to implement grouping with virtual scrolling
Grouping on Dabble DB (December 2007 etc. are the groups)
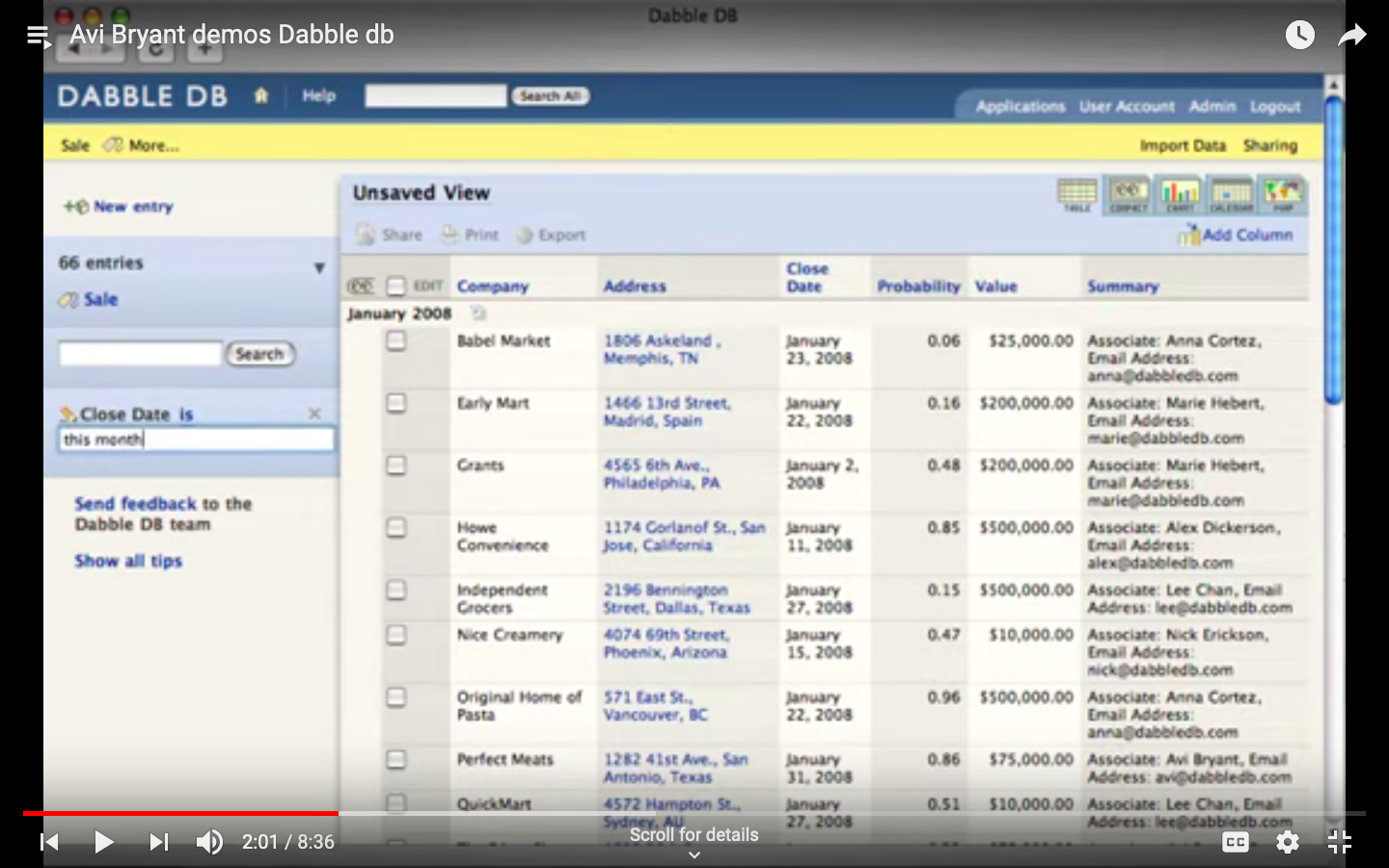
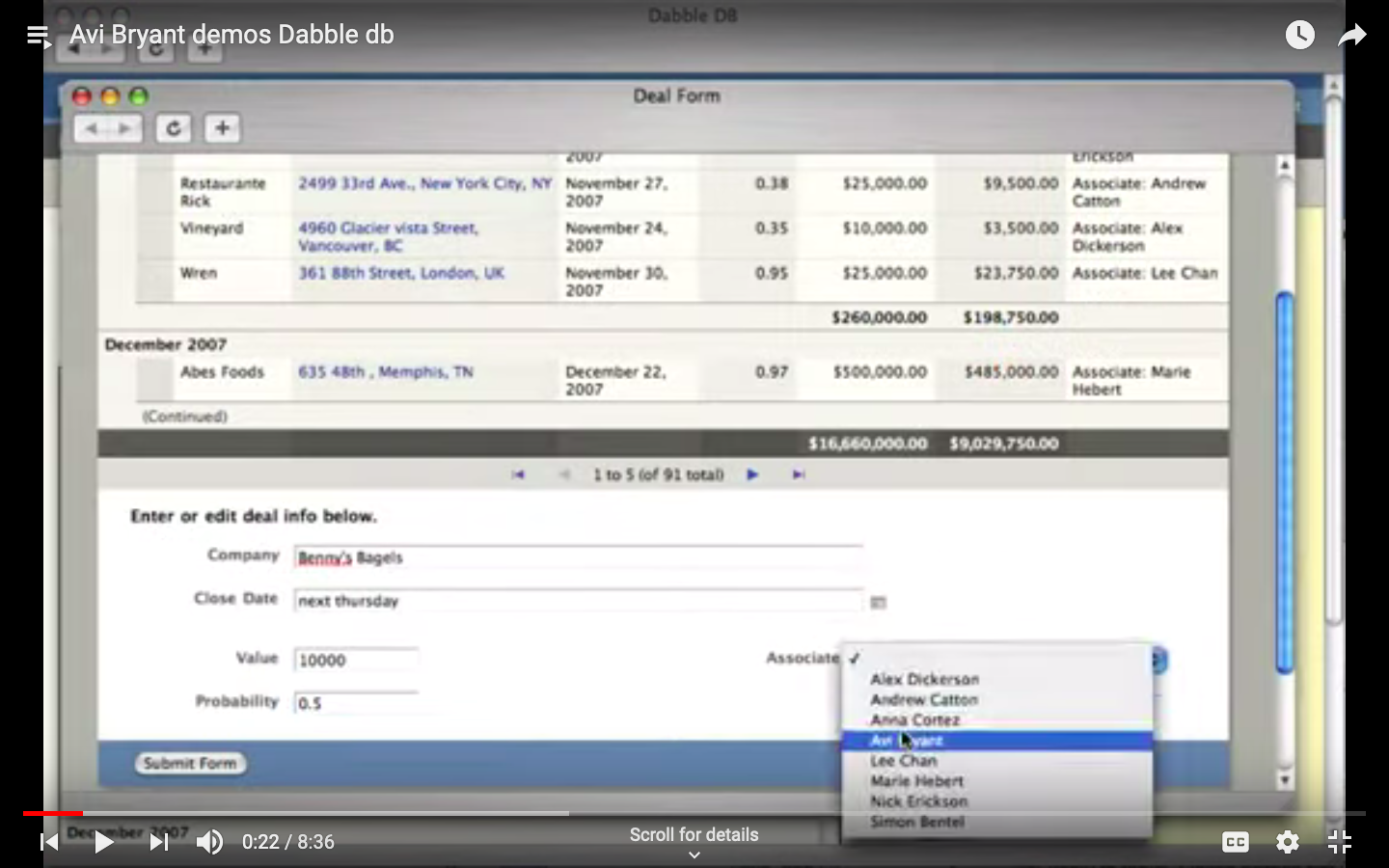
Ghislaine will update read only spec with pagination controls
Maubot¶
- GitHub Updates and Wiki Updates (private) rooms set up
- Let Kriti know if you want any plugins installed, list on README https://github.com/maubot/maubot
2021-05-17¶
Last week retrospective¶
Kriti¶
Not a very productive week.
- Meetings/conversations/discussions
- Matrix server setup
Pavish¶
Was only able to work for a couple days
- Discussions on readonly table
- Started working on table view
- Analyzed virtual scroll implementations
Brent¶
- Type casting, altering columns
- Implemented altering a column to a desired supported type
- Started discussions around different aspects of types / type casting from a UX perspective
- Implemented restricted / custom type casting logic based on outcomes of those discussions
- Overall, made less progress than hoped, but realized that some details needed clarification / buy-in before implementation made sense.
Ghislaine¶
- Readonly table wireframes and specs
- Setup design figma file and start defining components
- Update design wiki to include design documents
This week’s plan¶
We’ll be continuing with read only tables, table creation via data imports are next, followed by table editing (DML).
Kriti¶
- Set up Matrix bot
- File import API
- Sync DB and webapp if DB changes out from under webapp
- If I have time, handle TSV file imports (I might work with Joi on this if he’s interested)
Will also be working on CCI IT interviews and communication training.
Pavish¶
- Try and complete the read-only table view, with virtual scroll, accessibility and selection handling
- Discuss on ways to load data for table
- Handling row position change
- Merging buckets based on PK on UI
Ghislaine¶
- Add table via data import from CSV / Paste
- Define structure for figma component library
- Define basic typography styles
- Update design wiki to include design patterns
Brent¶
- Continue work on type casting, and type inference. We’ll be restricting attention to supported types only.
Interaction Patterns for Adding Tables¶
Three questions:
- Do we at some point want people to add multiple tables at the time?
- Yes, zip file of multiple CSVs or excel file where each sheet becomes a table
- Unlikely to add multiple tables in bulk from the UI without file import
- In videos, people create tables and define column types at the same time. Does that pattern make sense for us?
- Not during import. People can’t directly import CSV to Postgres, we automate that so people don’t have to pre-setup a table.
- Useful during table creation from scratch (blank).
- Blank tables, will discuss later.
Other Discussion¶
- When we import a CSV, along with allowing changing types, we’d also allow changing column namesj during an intermediary step in the UI
- The immediate table creation in the backend is just a backend implementation detail, the UI should still show a limbo state
UI Library and Font Choice¶
- right now, just using an Apple system font
- We probably want it to be an open-licensed font
- We need to make sure it has all the characters necessary
- It’s also important that we have something that does a good job with digits: 0 vs O, etc. (also consistent sizing)
Google Fonts¶
Google Fonts are open and could be one option
- Pavish likes Open Sans
System Fonts¶
System fonts might be good, better for performance (no need to load font)
- https://meta.stackexchange.com/questions/364048/we-are-switching-to-system-fonts-on-may-10-2021
- https://markdotto.com/2018/02/07/github-system-fonts/
Discussion¶
- Allowing user to use monospace font might be useful, especially for data entry
- Current font size does not work for small screens, Ghislaine will work on defining this better when defining the typography
- We will use relative sizes
- Ghislaine will find related article before next check in
- Use TypeScale to define font size https://type-scale.com/
Wednesday’s meeting¶
- Wednesday meeting moved two hours later
Technical spec / design / implementation process¶
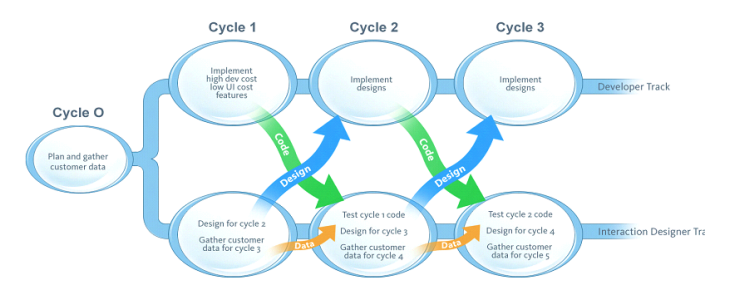
- We should be thinking in terms of finishing features end to end
- e.g. read only tables, table creation, table editing
- Ideally the process should be design –> identify decisions that need to be made –> make decisions –> finish design –> technical spec –> implementation
- we can’t do this for everything, and it wouldn’t make sense for everything
- think about things in terms of “high UI cost” and “high dev cost” and decide what to do
- hard to do things in parallel because we only have one person for each thing
- We could talk through our upcoming features to see if there are any “high dev cost” parts that we could get done before the design.
- Some things depend on UI (e.g. how are we conceiving editing a table, by row or by cell)
- Actually, editing a table is product decisions, not design decisions
- Some things depend on UI (e.g. how are we conceiving editing a table, by row or by cell)
Conclusion¶
Design work should happen serially, one feature at a time.
- We can try to have conversations in parallel, but it could get confusing, so let’s hold off for now and do one thing at a time.
- We might have cycles where some weeks are focused more on product decisions and research, others on implementation
- We can always start a GitHub discussion if inspiration strikes
Handling data load for table¶
- How to merge rows in UI when there’s no primary key?
- Maybe have a special read-only paginated (no-infinite scroll) display for tables without a primary key.
- Will continue discussion async
- Virtual scroll implementations – two different options
- Still deciding which option to use, Pavish will make a discussion with both approaches
- We might need to have a limit of 500k rows on a single page due to browser limitations on element height
- We cannot handle variable row height, need to figure out how to handle long data
- Grouping data should happen before table editing, since virtual scrolling will be affected
- We might want to wonder why the user is scrolling 500k rows, they may want to compare data between rows that are far apart and be frustrated that it takes time to load
- This is probably a separate feature, we currently just don’t want to break mysteriously with large tables.
2021-05-14¶
Import from CSV¶
Discussion of functionality
- We’ll support:
- Import local file
- Import file from URL
- Paste CSV/spreadsheet
- We can automatically detect file type, no need for user to enter
- Type inference
- Will it be done soon?
- Yes, Brent is working on it, we should assume it’ll be done by the time we’re implementing.
- Do we give advanced user the option to skip inference?
- Not for the MVP, to keep things simple
- We should show the user what’s happening in the background, show that the import is happening
- Show an indicator next to the table name
- Show the percentage to completion?
- We will have data to show (all strings)
- Do we allow the user to select columns to import?
- Not for the first iteration
- Schemas – users can either create a new schema or upload to an existing schema
- You can replace an entire table with a CSV or append extra rows to an existing table, but you can’t merge/deduplicate in the first iteration
- Error handling – show errors, we need error states
- Do we exclude only problem rows or reject the whole file?
- Reject the whole file
- It’s going to be confusing to see which rows were added and which weren’t
- Do we exclude only problem rows or reject the whole file?
- We need to show types in the read only table
- Icon for types, maybe an extra row that shows types in the header
- we probably don’t need to show an extra header row while looking at the whole table, metadata related to tables isn’t useful all the time
- idea: context menu for column that shows information about the column
- idea: hover over the column to see more information
- Not going to go into modifying types yet
- Icon for types, maybe an extra row that shows types in the header
- Will it be done soon?
- Provide a summary for tables to show fields and types
Custom type casts¶
- Postgres is far too liberal while casting types
- e.g. casting to boolean, “yesterday” becomes “yes”, which is True
- decimals –> durations casts to integers first
- What’s our appetite for risk here, especially since we have no undo?
- Option 1: Try very hard to cast (be okay with data modifications)
- Option 2: Be very conservative (refuse if we won’t be able to cast absolutely confidently)
- Option 3: (airtable-ish) delete data we don’t understand.
- We will probably need to support rules in the future, (e.g. “yes”/”no” in other language)
- We might have global inference rules in the future where we notice columns with only two options and ask them if they want to cast it to boolean.
- We’re casting at three different times:
- Automatic inference during import - this SHOULD be conservative
- User tries to manually cast – this should be more liberal
- Global inference (where we analyze the entire data and come up with inference suggestions)
- Not worrying about this one yet
- We might want to apply this at import for more “magic” (e.g. if column just has “yes” and “no” values, suggest boolean, if it has “yes”, “no”, “maybe”, suggest string)
- Inferring that columns are distinct would be useful
- e.g. OpenRefine notices that columns are almost-distinct
- We should not assume we don’t have an undo, we’re not trying to make the product as-is useful, we’re trying to make our MVP usable and we’ll have undo by the time the MVP ships
- Massively shifts balance towards being more liberal
- Mathesar should feel magical to work with: things we do for the user like converting data, making suggestions should enhance the user experience.
- But we should not do things without user approval/confirmation.
- Raja Parasuraman et al., “A Model for Types and Levels of Human Interaction with Automation.” Each line describes the tool as one of the following:
- Fully manual
- Showing the user every option
- Narrowing the options
- Suggesting the “best”
- Asking the user to approve an action
- Giving the user time to veto a selected action
- Keeping the user informed of actions that have been taken
- Responding to user inquiry about actions that have been taken
- Deciding when to inform the user of actions that have been taken
- Fully autonomous
- We’ll need to apply this scale to individual features.
- What do we do when the user tries to cast to a column and the data isn’t supported?
- We should try, if there’s an error and it’s nullable, then offer to delete the data that doesn’t fit.
- We might want customized actions based on types, but not for the MVP
- Users need to identify nullable / non-nullable column (field)
- also need to identify whether column is distinct/unique
- default value for column
2021-05-12¶
Design Hand-off Document¶
- Document Sections (UX, Interactions and UI)
- Wiki Entry for Deliverables
- Throwaway vs. permanent documents
- Throwaway documents will be published in a separate section on the wiki
- First design hand-off document is the spec for read only tables
- We’ll discuss the spec asynchronously
- Implementation phase will be documented after we actually implement a spec
New Matrix server¶
- matrix.mathesar.org
- Accounts limited to core team
More wiki updates¶
- New navigation
- Concepts page updates
- https://wiki.mathesar.org/archive/product/concepts
- Design inspiration section:
- https://wiki.mathesar.org/archive/product/design/exploration/data-types
New GitHub issues¶
Frontend workflow issues
- https://github.com/centerofci/mathesar/issues/123
- https://github.com/centerofci/mathesar/issues/124
Icon library issue
- https://github.com/centerofci/mathesar/issues/125
- Assigned to Ghislaine and moved to active work
- Noun Project icons don’t all have the same license, probably worth finding a different icon set.
- Icon set ideas
- Feather Icons
- Font Awesome
- https://fontawesome.com/license/free
- Material Design Icons
- Icon set should offer SVG
- Font Awesome offers SVG
2021-05-10¶
Ghislaine’s Design Process¶
(Ghislaine shared Miro board via screenshare)
The process is documented on the wiki: https://wiki.mathesar.org/archive/product/design/process
Steps¶
- Discovery
- Definition
- Design
- Design problem framing
- Point of view, goals, constraints
- Explore possibilities
- Prototyping
- Testing
- Development
Explanation¶
- Kriti & Brent did discovery and definition before Ghislaine joined, Ghislaine had to do some of her own work on this.
- “Definition” is our product roadmap
Discussion¶
- We don’t want to go in circles on definition, we should take our product roadmap as our strategy for now
- We shouldn’t be adding things to the roadmap, but we’ll need to clarify or remove certain things.
- We’ll review the roadmap before next time to make sure essential architectural things are on it:
- e.g. undo functionality, localization
Design Principles & Closing Design Issues¶
- Ghislaine has rough notes that she’s still organizing
- Principles are a manual for making decisions so that the designer doesn’t have to be involved in every decision
- Two different targets for design:
- Process-oriented: Enabling community & co-creation
- Result-oriented: Users accept product features, and we can measure acceptance.
- We design for impact and for implementation (not research and discovery and pushing boundaries, at this point)
- Competing options - we decide based on something that’s implementable sooner and have the optimal impact on the users
- e.g. increased effort for users has a big impact (may not be positive)
Principles draft¶
- Change plan if circumstances change
- Sufficient documentation to justify design decisions
- Shared sense of ownership on design
- Anticipate effects of project results on the user (we might not be right, but we try)
- Communication methods increase mutual understanding but do not delay work
- Regular contact with key stakeholders of the project
- Make invisible work visible to the user to build and maintain trust
- The work and how to do it is based on knowledge, not belief
Discussion¶
- It’s important to facilitate users becoming developers, so integrating both process and result is essential
- We can try to help users create the results they want through their own development
- Having a design system will be helpful so that developers don’t have to worry about design, and design system changes can be handled separately
Upcoming Features¶
What’s next after read only tables?
- Table creation from file import
- Records editing (DML)
- Table manipulation (DDL)
TODO: Kriti to add DDL and DML to wiki
Last week retrospective¶
Pavish¶
- Tickets and implementation for client routing takeover. See current PR.
- PR raised also:
- includes changes for npm dependency reinstall on starting containers (based on our discussion in Matrix channel)
- moves existing front-end to svelte
- loads pre-rendered data for implemented routes + through API on second visit
- handles scss preprocessing
Kriti¶
- Mainly wiki updates, took longer than expected.
- Some API work
- finished records API
- updates to schema API (to unblock Pavish)
- database keys API (to unblock Pavish)
- Licensed Mathesar under GPL.
Brent¶
- Finished testing of old prototype code
- Got into types.
- Implementation of type casting: Quick, easy (maybe 80 LOC)
- Testing of type casting: Complex, and raises a number of questions (ongoing)
- Overall, the main difficulty is mostly UX concerns; the implementations are generally easy.
Ghislaine¶
- Wireframes and UI exploration.
- Created issues for design tasks.
- Started draft for UX principles, but wanted to experiment a bit with the process before moving forward
- Defined initial UI design in Figma.
- Wiki updates.
This week’s plan¶
General plan is to focus on layout and read-only table view, and if no work is needed on that front, focus on supporting upcoming features decided above (probably file import). * Question (from Brent): Is there any support needed in the DB that doesn’t currently exist? * No, but types support the upcoming import flow
Pavish¶
- Create tickets and work on reusable components required for UI, without finalized css
- Textbox (text, password, number, email)
- Buttons
- Checkbox, Radio
- File drag & drop import
- If I get time,
- custom select box (has the most work - thinking of importing code from one of my open-source projects: select-madu)
- Discuss and decide on table view read-only UI
- Will not be available during usual working hours on Tuesday and Wednesday, since I have conflicting meetings with my current job
Brent¶
- Continue with types, unless there’s something more pressing (it’s not really related to the week goal, so I can flex if needed)
- Specifically, I want to bring some precision to the mapping between the types in the roadmap and implementation, and make sure we’re on the same page for each and every one.
- (Note from Kriti: that would be great)
- Finish type casting (it’s actually done, but the previous applies)
- Move on to type inference (easy once we’ve made all necessary decisions about each type implementation)
Kriti¶
- Sync DB and webapp if DB changes out from under webapp
- API updates needed for read-only table view
- File import API
- Set up some more infrastructure for Mathesar (wiki update bot, GitHub bot)
- might need separate Matrix server
- If I have time, handle TSV file imports (I might work with Joi on this if he’s interested)
- (note from Brent: If you switch to using the
psycopg2.copy_expert(which I recommend), this will be extremely easy)
- (note from Brent: If you switch to using the
I’ll be spending some time on hiring IT support for CCI.
Ghislaine¶
- Finalize first version of design process (diagrams, additional activity details)
- Complete UI for read-only tables
- Present UX principles and add first draft to wiki
Read-Only Tables¶
What decisions do we need to make in order to design and develop read-only tables?
- How users locate tables
- Sidebar navigation
- Naming tables
- Bookmark
- Recent
- Search across table
- How users prepare tables
- Opening a table to read
- Browsing table content
- Verify record count (basic table stats)
- Finding a table record location
- View options/pagination
- Save query (AWS Athena)
- How user confirms table content
- Real time editing / data accuracy
- Is it updated?
- How user executes table reading
- Filtering?
- Sorting
- How user modifies table reading
- Open another table
Questions from Engineering¶
- How do we handle an existing database with thousands of tables or schemas in the sidebar?
- How do we handle a table with hundreds of thousands of records?
Discussion¶
- AWS Athena as an example
- Left pane has your tables
- You can create tabs for different queries (on any tables or combinations of tables from the left pane)
- You can run the queries
- When you change tabs, the results change to match the displayed query.
- You can save a query so that you can close a tab, and get back to it (it reopens in an editable state)
- Tabs from last time are still open when you log back into the account.
2021-05-07¶
Wiki restructure walkthrough¶
- New Product section
- new Concepts page
- New Engineering section
- Community & Meeting Notes section moved to the root
Wiki purpose¶
- Spending time on the wiki now to set up structure
- We should all get into the habit of updating the wiki/documentation regularly, to make it accessible for future contributors / onboarding
Wiki updates review process¶
- We want to keep review process minimal, since we’ll be updating the wiki frequently
- Major wiki changes should be reported in code review channel and appropriate people tagged
- Use your discretion
Future ideas¶
- Blog hosted on the wiki (can post to Hacker News, etc.)
- Blog post page type is on the wiki.js roadmap
Keeping the wiki up to date¶
How do we make sure the wiki stays up to date?
- Wiki should not need to stay in sync with the code, it should be for higher level documents/specs
- We should update wiki when:
- Designing new features
- Concluding GitHub discussions
- Making major technical decisions
- Previously, wiki was used for things that belonged more in GitHub discussions, so that caused it to go out of date quickly
- Kriti will keep an eye on making sure the wiki is up to date
- We should figure out how to post wiki updates to Matrix
Figma designs¶
(Ghislaine demoed Figma designs)
- Designs are exploratory but general feedback is welcome
- Icons should always be accompanied by labels
- Lots of questions coming up, decisions need to be made
- Going simple on UI design
- Icons are Noun Project
Questions and Discussion¶
- What does the pagination look like?
- Header, etc. should be sticky
- Are views in Mathesar separate from database views?
- Mathesar views are backed by database views
- Are forms views?
- Are calendars views?
- Maybe forms and calendars should be different from views
- Can make the decision later
- Will we support sorting, grouping, etc. on Tables?
- Yes, but if you want to save it, then it’ll be made into a View
- Will we show the ID in the record view?
- Yes
Ideas¶
- Pinning columns would be good to help users identify important columns
- Can we get back to the record you were editing if you open a record form and go back to the record view?
- It’s doable
Next steps¶
- We’ll start with designing the general layout and read-only table
- Pavish & Ghislaine will make a list of what decisions block this from their end
- We’ll also decide on Monday what we’ll work on after the read-only view so we can start planning on decisions that need to happen on backend/design front
Local Development¶
- Image is constructed after package install
- typical for prod
- requires rebuilding when new packages are installed
- Could do the installation in docker-compose
- Improve documentation ASAP
- Will continue discussion async
2021-05-05¶
Internship update¶
- Eamon is now starting on May 24.
Hand-off design to development¶
Questions¶
- What does design need to consider as part of the hand-off to development process?
- How does the implementation planning process look like for design solutions?
- How do we test and refine design solutions as part of this process?
Discussion¶
- Waiting on the entire design to be done before starting frontend developmment seems like overkill
- Pavish and Ghislaine can work in parallel
- e.g. Pavish can start on the basic table structure while Ghislaine is defining more complex interactions
- There will always be iterative changes even after a module is developed
- There should be design review meetings to catch small issues (like selecting multiple options instead one)
- Design reviews will be all four of us, since it impacts the backend
- We’ll use existing Mathesar check-in meetings for design reviews, it will be an agenda item
- Ghislaine will post the link to the Figma project beforehand
- Review meetings should take care of testing/refining desigh solutions
- Once we see it live, there will be some refinements noticed that will involve additional issues being created.
Staging environment¶
- We should set up a staging environment with real data
- Consider the team using Mathesar to keep track of project related information
- User interview ideas
- Non-code related todos
- Have a large (millions of rows) database stored on staging so we can identify issues
- Set it up on RDS or GCP equivalent so that we can make sure it works
- Consider the team using Mathesar to keep track of project related information
- It would be good for all of us to have our own private instances of Mathesar as well that we use regularly
Design Prototyping Sandbox¶
What environment can we create so that design interactions can be built and experienced as prototypes by the team or internal/external stakeholders.
- Would be good for Ghislaine to have access to our components so that she can design with HTML
- Single source of truth for all styles
- Ghislaine would be building static HTML files with some javascript from existing components, there’s no need to edit existing files on production
- Potential solutions
- We could have a Storybook for components, but it wouldn’t work for entire application pages
- Ghislaine could download latest CSS from client builds
Solution: for now, just download latest CSS and apply to local HTML files
- Pavish can help Ghislaine set up a local development environment when ready
Ghislaine will match CSS class names to Figma components.
Design Principles & Closing Design Issues¶
- Ghislaine is working on these on parallel with Figma designs
- We’ll discuss on Friday
Mathesar Philosophy¶
Exposing DB Structure via Object View of Data¶
- Databases are different from spreadsheets because they’re actually less table oriented
- Fundamental structure is record, everything is relationship between records
- Tabular view is useful for some things, but is limited
- Just because databases have tables, doesn’t mean we should only be focused on tables or everything needs to be a table
- Eventually we will be able to handle non-rectangular data, Postgres can do that
- Table is the default view, but we’ll support kanban, cards, calendar etc.
- Ghislaine will share paper on spreadsheet vs. record design from MIT
- We need a record view
Plugins¶
- People should be able to build their own views and types as plugins, probably more
- Maybe aggregations or groupings, other types of data manipulations
- Too early to discuss plugin architecture in any detail
- Mathesar is a “swiss army knife” for data, people should be able to build their own set of tools, not just have a pre-configured set of tools
- We should handle reflection really well etc. to make Mathesar useful for power users
Routing¶
(Pavish demoed local Svelte-rendered Mathesar for CSV upload form)
- Currently working on table view
- Routing is handled client-side
- Need API for database name and table names in schemas
- Kriti will work on this today
- Discussed best way to render JSON data in the Django template
- We will switch to using serializers to get data and pass it to the template via context
- this will also ensure that the format matches the API and allows consistency when working with the API
Design section on wiki¶
(Kriti demoed work on Design section on wiki)
- Ghislaine will update wiki later with Design Principles & Design Process
2021-05-03¶
Meetings¶
- Meetings are three times a week now
- We should continue to use Mondays for planning the week out + any discussion.
- Wednesdays and Fridays should be for general updates/discussion/talking through problems. ideally, we’ll have an agenda in advance (nothing formal, but someone should have a topic they want to talk about or brainstorm/bounce ideas off of people) and cancel the meeting if there’s nothing to talk about.
- We’re not going to cancel any meetings next week, just to see how it goes.
- We have to use the full hour, we’ll end early if we’re done with discussion.
- The plan is to have fewer meetings in the long term, doing things asynchronously is better for community involvement, documentation, etc.
- It’s important to have more meetings at this stage until we all fully grok the project and get to know each other better.
Last week retrospective¶
Pavish¶
- Set up frontend development environment and workflow - everything needed to get started with frontend
- Documentation - only updated README, see currently open PR
- Kicked off discussions for production build and E2E integration tests
- Too early for this right now, but we should keep it in mind
Ghislaine¶
- A round of wireframes for data exploration, discussions with Kriti
- Research revealed that BI platform vs. web analytics etc. all solve similar problems differently
- Went back to Dabble DB to look at it again with more information about what’s under the hood for us
- e.g. they don’t have “tables”, we want to expose more of the DB structure
- they made different layout decisions
- Created a document: Initial Research and Wireframing Conclusions
Brent¶
- Moved stuff over from the prototype repo to main repo
- Prototype used SQLAlchemy 1.3, current repo uses 1.4, which implements the “2.0 API” and deprecates a bunch of things
- Took a while to port over, especially
copymethod, which was deprecated for being non-deterministic/imprecise, leading to unexpected behavior- We had to implement our own
copymethod in a simplified Mathesar Column class
- We had to implement our own
- Ticketing
- Discussions
- e.g. function signatures - Kriti & Brent were using different types of signatures, and needed to get in sync
- Moving over stuff from the prototype is done, except for Jupyter notebook and random table creation, which will not be moved over
- Put together demo for Ghislaine and Pavish
- A bunch of bug fixes
Kriti¶
- Worked mainly on the API
- Mostly done
- CRUD on records (no PUT (not necessary))
- Read-only on schemas and records
- Mostly done
- Did work on testing
- Django
- CSV uploading
- API
- GH actions to run tests on PRs
- Simplified Issue templates a bit
- Meetings, 1:1s, planning, licensing discussions
This week’s plan¶
Pavish¶
- Implement routing on client (take over from server after initial page load)
- Table view using Svelte
Ghislaine¶
- Learned enough from the wireframing process, we can go higher-fidelity
- Will work on creating UI for inventory use case in Figma
- No design system yet, since it’ll just slow things down
- User will be working with views
- Write down Mathesar principles to make decisions
- Talk about how to close design issues
Brent¶
- Writing tests for last week’s functionality
- Types and type inference
Kriti¶
- Update wiki, roadmap, usecases & concepts. Better documentation.
- Sync webapp and db tables
- GPL for Mathesar
- Update CSV import to save CSV file
- API for CSV import
- One API for uploading CSV
- One API for showing 10-20 lines of CSV
- Status of CSV upload
- API to actually create table
- If time permits, allow TSV import (to be co-ordinated with Brent)
Community readiness check-in¶
- License
- GPL
- Roadmap
- Kriti to update wiki
- Tickets
- Still a few weeks away from making publicly contributable tickets
Other Discussion¶
URL Routing¶
- Routes might need to be duplicated in both backend (Django URLs) and frontend, since we need to handle routing from both places depending on whether the user is already in the application
Exposing DB Structure vs. Object View of Data¶
- Not mutually exclusive to expose DB structure and let people work in different views
- Discussion will continue async
CSV Uploads & Type Inference¶
- Current workflow is to upload a CSV file directly, we want to change it to store the CSV file, show 20-30 lines to the user, infer types, allow users to change types, and then create the table.
- Type inference should be in the database, not Python so the fastest way to infer is to make a table full of strings first.
- Type inference - public function signatures
- Infer a type for a column
- Infer types for columns of an entire table
- Automated flow –> upon upload, show types to the user
- Discussion will continue async
Closing Design Issues¶
- How to close design issues on GitHub? What needs to be done?
- Discussion will continue async
Matrix-related Discussions¶
- Tech discussions should happen in the Mathesar public channel where possible.
- Set up a separate code review channel for PR review requests.
- Mittens says “miaow”